As an effort to make Linux desktop a cozy environment for Thai users, I find input method implementation is an issue worth a dedicated page for developers' documentation. This page will brief to you the theory behind the de facto Thai input method specification, as well as the status of current implementations on GNU/Linux desktop, and developer's implementation guide.
This section is not an elaboration of the details of Thai writing system. Rather, it is intended to be a background of the requirements of Thai input/output method.
Thai is written from left to right, with stacking of combining marks above or below the base consonant, like diacritics in European languages. However, although the visual concepts of Thai combining marks and European diacritics are quite similar, the implementations are different.
First, Thai has too many possible combinations of base consonants and combining marks to be enumerated like Latin accents in ISO/IEC 8859 series. Therefore, it encodes combining characters in separate from base consonants.
Second, Thai combining marks are classified into upper/lower vowels, tone marks, and other diacritics. And a Thai base consonant can be combined with up to 2 combining marks, that is, zero or one upper/lower vowel and zero or one tone mark or diacritic. The upper/lower vowel, if present, is always attached to the consonant before the tone/diacritic. These combining marks conditions need to be governed by some rules to limit the number and order of the combining characters to be put after the base consonant.
As a third difference, Thai users are familiar with typing the combining characters after the base consonant, in contrast to many European input methods in which users type the diacritic before the base letter to compose an accent. Therefore, the input method, as well as other string processings, are expected to assume this typing and storage order.
Prior to Unicode, there was a common convention agreed upon by vendors for implementing Thai, called WTT 2.0, based on TIS-620 eight-bit character set. (WTT, pronounced Wor Thor Thor, is a Thai abbreviation of Wing Thook Thee which means Runs Everywhere.)
In the same manner as Unicode normalization, WTT 2.0 defines canonical order of Thai character strings. It differs, however, in the implementation details, and in terms of syntactic strictness.
First, WTT 2.0 requires strings to be stored and transmitted in canonical order, not to be normalized at processing time. Therefore, in WTT 2.0, canonical and non-canonical strings mean different things and may yield different results in rendering, sorting, searching, and so on. This helps simplify the string handling routines at some degree, leaving the task of ensuring the order at a single point, the input method.
Second, as a difference in detail, WTT 2.0 concerns more in syntactic soundness of the input string. For example, WTT 2.0 does not allow more than one tone mark to combine in one cell, while Unicode does. Moreover, WTT 2.0 defines 3 levels of syntactic strictness of input method. Level 0 (Passthrough) does not filter at all. Level 1 (BasicCheck) just ensures the input sequence to comply to canonical order and can be displayed gracefully without fallbacks in the output method. Level 2 (Strict) is more picky in filtering out some unsound sequences.
Therefore, we can see that WTT 2.0 condition is stronger than that of Unicode in terms of string ordering. WTT 2.0 input method produces strings of a proper subset of that of Unicode specification, and thus does not have bad effect on Unicode-compliant programs. Rather, it would help filter out strings that are considered illogical for Thai users. (Likewise, WTT 2.0 output method also makes those strings obviously distinguished to human eyesight.)
However, the opposite direction is not true. Since WTT 2.0 programs rely on a stronger condition than that of Unicode, they can behave differently when processing some Unicode strings which should otherwise be normalized to be canonical. Hence, while it's safe and benefitial to implement WTT 2.0 input method for Unicode applications, applying general WTT 2.0 applications in Unicode environment needs their algorithms to be more fault-tolerant.
So, to take the advantage of WTT 2.0 friendliness, a Thai-supporting program should comply to the spec, meanwhile handle the weaker conditions of Unicode with fallbacks to survive in the environment. And the WTT 2.0 input method can be used to filter out those weak conditions.
WTT 2.0 classifies characters in TIS-620 into 17 types.
A single table, shared by the input method and output method, is defined for describing the ordering conditions:
| C T R L |
N O N |
C O N S |
L V |
F V 1 |
F V 2 |
F V 3 |
B V 1 |
B V 2 |
B D |
T O N E |
A D 1 |
A D 2 |
A D 3 |
A V 1 |
A V 2 |
A V 3 |
|
| CTRL | X | A | A | A | A | A | A | R | R | R | R | R | R | R | R | R | R |
| NON | X | A | A | A | S | S | A | R | R | R | R | R | R | R | R | R | R |
| CONS | X | A | A | A | A | S | A | C | C | C | C | C | C | C | C | C | C |
| LV | X | S | A | S | S | S | S | R | R | R | R | R | R | R | R | R | R |
| FV1 | X | A | A | A | A | S | A | R | R | R | R | R | R | R | R | R | R |
| FV2 | X | A | A | A | A | S | A | R | R | R | R | R | R | R | R | R | R |
| FV3 | X | A | A | A | S | A | S | R | R | R | R | R | R | R | R | R | R |
| BV1 | X | A | A | A | A | S | A | R | R | R | C | C | R | R | R | R | R |
| BV2 | X | A | A | A | S | S | A | R | R | R | C | R | R | R | R | R | R |
| BD | X | A | A | A | S | S | A | R | R | R | R | R | R | R | R | R | R |
| TONE | X | A | A | A | A | A | A | R | R | R | R | R | R | R | R | R | R |
| AD1 | X | A | A | A | S | S | A | R | R | R | R | R | R | R | R | R | R |
| AD2 | X | A | A | A | S | S | A | R | R | R | R | R | R | R | R | R | R |
| AD3 | X | A | A | A | S | S | A | R | R | R | R | R | R | R | R | R | R |
| AV1 | X | A | A | A | S | S | A | R | R | R | C | C | R | R | R | R | R |
| AV2 | X | A | A | A | S | S | A | R | R | R | C | R | R | R | R | R | R |
| AV3 | X | A | A | A | S | S | A | R | R | R | C | R | C | R | R | R | R |
The rows are for types of previous character, and the columns are for types of next character. The codes in table cells determine the condition of the order:
Input method should behave as follows:
Output method should behave as follows:
As an extension to the aforementioned WTT 2.0 input sequence checking, some applications also add a capability of correcting the illegal sequences. This is considered an advanced feature.
To add such capability to free/open-source software, I have proposed an extension rule, based on the WTT 2.0 table, as follows:
Let
CP(x,y) = true if value at (x,y)
in WTT 2.0 table is `C'.
z = next character
y = previous character
x = character previous to y
begin
if CP(x,z) then
if CP(z,y) then
reorder(y -> zy) // e.g. ก่ + -ี -> กี่
elif CP(x,y) then
replace(y -> z) // e.g. กิ + -ี -> กี ; ธ์ + -ู -> ธู
elif y is FV1 and z is TONE then
reorder(y -> zy) // e.g. นำ + -้ -> น้ำ ; ทา + -่ -> ท่า ;
// นะ + -่ -> น่ะ
else
reject(z) // e.g. กา + -ี -> กา ; กเ + -่ -> กเ
endif
elif AC(x,z) then
replace(y -> z) // e.g. เ + แ -> แ ; กแ + ฤ -> กฤ ; ฤก + ๅ -> ฤๅ
else
reject(z) // e.g. ธุ์ + -ู -> ธุ์
endif
end
Technical requirements of Thai WTT 2.0 input method can be considered distinguished from other existing input methods:
Rather, its requirements are:
The key-to-character mapping is easy to understand. Thailand has its industrial standard for keyboard map, based on traditional typewriter.
The ability to retrieve context character from application input buffer is for validating the key events, according to the table above. Note that other solutions are not adequate, for example:
The last requirement of read/write access to application input buffer is for the input sequence correction extension.
X11R6 defines X Input Method (XIM) as an event filter for X client. Being a filter, it intercepts all the events passed to the X client, selectively manipulates the ones related to text input, namely keyboard and mouse events, and passes all the rests to the X client. This way, the input method can convert the key press sequences from user into appropriate character strings for X client. This allows languages with huge character set, such as Chinese, Japanese and Korean (CJK), to be input with limited keys on the keyboard.
For those complicated input methods like CJK's, whose duties are as hard as converting pronunciation into appropriate one from thousands of characters, XIM is implemented as a separate process which communicates with X client through client-server model. But for some languages, such as English and other European languages, whose input methods are just one-to-one mapping from key to character, plus some simple accent composing, doing so is a waste of resource. Therefore, the X library has also provided the input methods internally so the communication with X client becomes mere library function calls.
Fortunately, Thai appears to be one of the languages whose input methods are provided in the X library (since X11R6). Apart from key-to-character mapping, it also checks and rejects illegal sequences according to WTT 2.0.
X11R6.1 introduced Thai XKB map using Latin keysyms which map to ISO/IEC 8859-1 characters with the same eight-bit binary values as the desired TIS-620 Thai character codes. This was considered a dirty hack which could deceive applications with poor internationalization for a while.
However, it had been only the XKB part that actually worked for Thai. The Thai XIM was first activated by the presence of th_TH locale in glibc 2.1.1, but failed to translate special keys, and Thai users were recommended to disable it either by setting LC_CTYPE=C or by setting XMODIFIERS="@im=none".
The first change to Thai input method was marked by Pablo Saratxaga's patch in XFree86 4.0.1d to use genuine Thai keysyms in Thai XKB map. This rendered Thai input to be completely dead. It indeed required another appropriate XIM to translate the Thai keysyms into TIS-620 characters. One suggestion was to create a dummy th_TH/Compose file so that the local XIM designed for European languages was exploited to serve the job. However, as some Thai developers were aware of the presence of Thai XIM in X library, another effort to repair the Thai XIM was created. (See XFree86 Thai Support page for details.)
After a sequence of patches, the Thai XIM was finally repaired and started to work since XFree86 4.0.3 and 4.1.0 (in different branches). Especially, the context retrieving code had also been introduced in XFree86 4.1.0.
There had been no significant patch for Thai XIM in XFree86 until after version 4.2.1. The effort for a more complete XIM was reactivated, and the input sequence correction capability was then introduced.
Please see the XFree86 Thai Support page for more details.
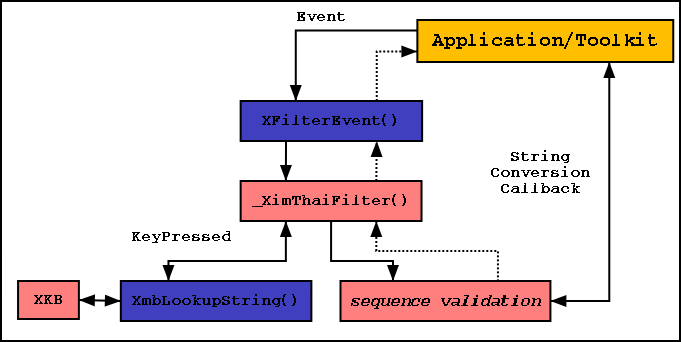
There are two major parts, in addition to the WTT 2.0 concepts, in understanding how Thai XIM works. One is the event filtering mechanism, the other is the callback for accessing the client input buffer.
To use XIM, a client must open a connection to XIM using XOpenIM() function, and then create Input Context for each widget using XCreateIC() function.
Then, in its event loop, it calls XFilterEvent() function to pass the event to the XIM filter function. If the filter has absorbed the event, it returns True, and the client should discard the event. Otherwise, the client should continue processing the event.
The filter function for Thai XIM is _XimThaiFilter(), an internal function in X library implementation. It returns False (i.e. doesn't absorb the event and pass it through) for all unrelated events, such as non-keypress events and keypresses of special keys or non-printable characters. For printable character events, it validates the character. If the key is invalid, it beeps and returns True (i.e. absorbs the event). If the key is valid, it converts the character and fills up the multi-byte, wide-char, and UTF-8 compose buffers in the Input Context, before putting a zero-keycode event back to client's event queue and returning True. The return value True tells the client to discard the event. But the zero-keycode event will be fetched soon. Then, the XIM filter will just pass it through by returning False and let the client process it using appropriate X*LookupString() function.
The XmbLookupString(), XwcLookupString(), and Xutf8LookupString() functions are used for converting key event into character string or keysym. Internally, they are wrappers to the XLookupString() function, which converts raw keycode into logical keyboard symbol (aka keysym) and then to character string via XKB rules. The string returned from XLookupString() are then converted into appropriate encoding by the wrappers.
However, the wrappers also support string passing from XIM via the Input Context compose buffers. If the zero-keycode key event is passed, they will look for string in the corresponding compose buffer and will return that string immediately. And that is how Thai XIM passes the accepted characters to the client.
As stated above, Thai input method is context-sensitive. Fortunately, X11R6 also defines a callback to be provided by X client so that XIM can call to access its input buffer: String Conversion Callback. The callback, as implied by its name, is intended for converting the string in the input buffer into something else, such as from pronunciation to character string. However, such conversion is composed of retrieving and substituting the content of the input buffer. These just apparently fit the requirement of the Thai XIM.
So, Thai XIM requires cooperation from X client by providing the callback function and setting the XNStringConversionCallback Input Context value to point to it (by means of XSetICValues() function).
The callback must handle two operations for the conversion: XIMStringConversionRetrieval and XIMStringConversionSubstitution.
The retrieval is a request to read the content of the input buffer of specified range. The substitution is a request to delete content of specified range. The details of the usage and semantics of the callback can be found in the Xlib - C Language X Interface document within X11R6 distributions. In X11R6.4, it is described in Section 13.5.1.7 (Input Method Overview -- Callbacks) and Section 13.5.7.3 (Input Method Callback Semantics -- String Conversion Callback).
In summary, here is the list of what an X client needs to do to support Thai XIM:
GTK+ 2 input method, like its Pango framework for multilingual output method, has been modularized so that various individual input methods can be implemented as loadable modules. Most of these input methods just handle GDK key events without XIM hands.
However, one of the input method modules (or in short, immodule), called imxim, still bridges the framework to the traditional XIM, so XIM users still have a chance to use their favourite input methods with GTK+.
The CJK implementation in the imxim of GTK+ 2.1.3 is more than enough for establishing connection to Thai XIM. The only thing left is the input buffer accessing.
Fortunately, GTK+ 2 API has been gracefully designed to handle it. A GTK+ widget can provide access to its input text buffer by handling the retrieve_surrounding and delete_surrounding signals.
The GtkIMContext class is a base class representing a widget's text input context. The communications between immodules and widgets are done through this class interface, just like XIC for X.
Then, when an immodule needs to read the widget's input buffer, it calls gtk_im_context_get_surrounding() method upon the GtkIMContext instance that represents the widget. The method will emit the retrieve_surrounding signal to the widget, who handles the signal by copying its context into the GtkIMContext via the gtk_im_context_set_surrounding() method.
Likewise, a GTK+ widget can also provide input buffer deletion by handling the delete_surrounding signal, which is emitted by the gtk_im_context_delete_surrounding() method issued by the immodule.
Thanks to the internationalization effort of GTK+, the GtkEntry widget has handled both signals from the beginning! Therefore, the only jigsaw left is to make the imxim bridge the gap between the XIM and GTK+ widgets.
I have proposed an imxim patch for this. Unfortunately, I cannot make it to be included in GTK+ 2.2, due to some problems in interpreting the X protocol from the manual. The discussion can be found in GNOME bug #101814 and XFree86-i18n mailing list.
In addition to imxim, it is also possible to create an immodule for Thai, which can bypass the complicated XIM protocols. In GTK+ 2.0, there actually is an immodule named imthai-broken, which is, as it says, still broken. Its implementation is to borrow the European composing method provided by the GtkIMContextSimple class. Therefore, it does not check the input sequence at all.
However, it serves well as a draft for a more complete Thai immodule. So, I have also prepared an imthai patch to add imthai module. GtkIMContextThai implementation class is introduced in filtering GDK key events according to WTT 2.0, plus input sequence correction. In the class, context is retrieved using gtk_im_context_get_surrounding() and corrected using appropriate gtk_im_context_delete_surrounding() calls to delete character in widget's text input buffer. Finally, the net characters are committed to the widget through the commit signal. All are done in GTK+ way. (See followups in GNOME bug #81031.)
In summary, upon GTK+ 2 input method abstraction, to provide smooth Thai text input, all that a GTK+ widget or application needs to do in addition to ordinary text committing tasks is handle two more uncommon signals:
An example of such implementation can be found in the GtkEntry widget itself. And I have also proposed a Gnumeric patch (as a followup to GNOME bug #84062) based on it.
In case the retrieve_surrounding and delete_surrounding signals are not handled by the widget, the IM falls back by remembering a few characters last typed in. However, the memory is lost in some key events which affect cursor position, such as PgUp, PgDn, Home, End, Backspace, etc., and the IM will cease to behave in accordance with the new context. For example, any combining character will be rejected, although it is combinable with the base consonant laying before the cursor, unless you type some base consonant first. Therefore, GTK+ applications are recommended to handle these signals for smooth Thai inputting.
|
Theppitak Karoonboonyanan |
Copyright © 2003, 2004 by Theppitak Karoonboonyanan. All right reserved.