A subsystem decomposes a codebase into smaller, cohesive units. Two primary axes of decomposition exist:
Technical axis: grouping by component type (controller, service, model, view)
Functional axis: grouping by business capability (cataloguing, circulation, etc.)
1.2 Tension Between Framework Prescriptions and Decomposition Strategy
Organizing top-level subsystems functionally may create friction with frameworks that prescribe a technical-first structure. Concrete examples:
Rails enforces model, view, and controller directories at the root level, making functional decomposition awkward without additional mechanisms like Rails Engines
Sinatra (a microframework) imposes minimal structure, leaving architectural decisions entirely to the team
Frameworks with rigid prescriptions constrain architectural choices. Frameworks with no structure shift the entire burden onto the team with no guidance. This second approach might be fine for teams that know what they are doing and how to shape the architecture properly. Not everyone needs guidance from the framework.
1.3 Contexts as a Middle Ground
Phoenix provides contexts as a compromise:
Explicit, guideline-oriented subsystems that enable functional decomposition without rigid enforcement
Contexts define functional boundaries while allowing technical organization to remain nested within them
Functional blocks may later evolve into microservices, but this is optional
The same decomposition serves equally well in a modular monolith or a distributed architecture
The choice depends on team needs, scaling requirements, and operational maturity, not on the decomposition strategy itself
2. Pipeline Topology and Data Flow
2.1 The Unix Pipeline Model
Unix pipelines model data flow through a single stream connecting stdout to stdin. This forms a linear chain where each stage's output becomes the next stage's input. Key characteristics:
Each stage has exactly one input and one output
Cognitive overhead is minimized because the topology is trivial to trace
The linear, single-stream characteristic is not mandatory for a pipeline, but it reduces complexity significantly
2.2 Arbitrary DAG Topologies
Orchestrators like Airflow allow arbitrary DAG topologies with fan-in and fan-out edges. Tradeoffs:
Powerful for expressing complex dependencies
DAGs with dense interconnections tend to become hard to read even with visual rendering
Complex function-call topologies with many parameters outside Airflow and Unix pipelines also produce unreadable code
2.3 Byte Streams and Opaque Containers
Unix-like pipelines connect programs by passing data through unidirectional byte-streams:
Programs at each end agree on a structure such as JSON, CSV, or tar archives
The pipe mechanism itself transports only raw bytes
This has a direct analogue in dynamically typed languages: in Lisp and Clojure, collections (lists, maps, vectors) serve as opaque containers that can hold almost arbitrary data
The consumer interprets the contents rather than the container dictating them
3. Typing Heterogeneous Pipeline Data
3.1 The Problem
Strict type systems introduce complications when handling heterogeneous data flowing through a pipeline where each stage transforms the shape slightly.
3.2 Failed Approaches
Single large type with many optional fields:
Creates dependencies between all pipeline steps
Loses the ability to reject illegal data
Makes reuse difficult
Changes to one field propagate everywhere
Many separate types for each step:
Exhaustive and adds noise to the program
Structures may not be mutually exclusive yet are treated as such
Maintenance burden grows with every new stage
Both approaches fail because each pipeline stage depends on more than it needs.
3.3 Partial Fixes From Functional Programming
Two techniques alleviate but do not fully resolve the problem:
Functional record update: enables creating modified copies without mutation, reducing coupling related to state changes
Sum types: restore the ability to discriminate valid from invalid data and support exhaustiveness checking
Remaining limitation: every step that pattern-matches on a sum type must know about all variants. Adding a new case still propagates changes through the pipeline.
3.4 Structural Type Compatibility
Structural type compatibility offers a complementary solution:
Independently defined types become compatible based on shape alone without requiring any inheritance relationship
A consumer can specify only the subset of fields it needs via a structural interface
Each step depends on a minimal projection of the data rather than the full type
This decouples pipeline stages more effectively than either naive approach or sum types alone
3.5 Python Implementation
Python implements several of these patterns:
dataclasses.replace(): supports immutable record updates
The | union operator: simplifies union type expressions
Protocol classes: enable structural subtyping, allowing independent types to satisfy contracts based on method and attribute signatures
Tagged unions: modeled using Literal discriminator fields on dataclasses or TypedDicts
typing.assert_never with mypy: enforces exhaustiveness checking on pattern matching or if chains, providing compile-time guarantees similar to sum types in functional languages
Combined approach:
Protocols decouple steps through structural conformance
Tagged unions enable variant discrimination with exhaustiveness checking
Functional record updates reduce mutation-related coupling
4. Microservices, Processes, and Isolation Patterns
4.1 The Shared Principle: Isolated State by Default
A microservice and a Unix process share architectural similarities:
Microservices: in well-designed architectures, a service does not share variables or databases with other services. Communication happens through well-defined interfaces. This is a best practice, not a hard technical constraint.
Unix processes: each process has its own virtual address space and does not share memory directly with other processes. Explicit sharing is possible through mechanisms such as shm_open (POSIX shared memory) or mmap.
4.2 Historical Lineage
Microservices on GNU/Linux are literally processes communicating via HTTP over TCP/IP. The historical chain:
TCP/IP: first implemented in 4.2BSD Unix in 1983
HTTP: developed at CERN in 1989 to 1990, building upon these networking foundations
Tim Berners-Lee wrote the first HTTP server and web browser on a NeXT workstation running NeXTSTEP in fall 1990
NeXTSTEP was heavily influenced by BSD Unix
GNU/Linux copied many initial ideas from Unix while remaining free and open
The modern distributed system traces an unbroken lineage back to Unix.
4.3 Pipes as an Alternative to Microservices
Piping via stdin-stdout chains is another mode of interprocess communication:
Not as powerful or generic as TCP/IP or HTTP
Easy to use and reason about
Naturally fits data pipelines
A data pipeline can be built using command-line tools piped together, running as processes on GNU/Linux instead of using microservices and a full orchestration system
Scalability can be achieved by SSH and distribution through GNU Parallel, which launches jobs across multiple machines accessed over the network
4.4 Erlang and Clojure as Additional Isolation Models
Erlang processes:
Lightweight alternative to Unix processes
Rich high-level interprocess communication via mailbox message passing
The Erlang VM enforces process isolation as a runtime guarantee
Clojure and other functional runtimes:
Do not have the same process isolation constraints as the Erlang VM
Provide lightweight isolation via persistent data structures and Software Transactional Memory (STM)
STM allows memory sharing while preventing conflicts even when multiple functions run in parallel or concurrently
Bottom Line: Think Twice Before Going Micro
Here is the real talk. You might want to pause before spinning up your first microservice. Ask yourself these questions:
Do I actually need physical isolation, or will logical separation suffice?
Can a simple pipe between processes do the job just as well?
Am I solving a scaling problem that does not exist yet?
Do I have the ops maturity to handle distributed tracing, service meshes, and deployment pipelines?
Will my team understand this architecture six months from now?
The truth is, Unix pipes have been doing data transformation reliably since 1973. Erlang processes have handled millions of concurrent connections since the 1980s. Functional isolation with STM has been working since Clojure showed up in 2009. None of these require Kubernetes. None of them need a dedicated platform team. And none of them will haunt you with debugging nightmares at 3am.
Microservices are not evil. They are just heavy. They are the nuclear option for isolation. Use them when the problem demands the weight. Otherwise, reach for the lighter tool. A pipe, a context boundary, a protocol type. Try the easy solution first. If it breaks, then scale up. Most teams never get to that point. And their systems stay simpler, cheaper, and easier to maintain because of it.
So yeah, think twice. Maybe thrice. Then build the smallest thing that could possibly work.
tl;dr – buffer overflow But it’s a bit special kind of overflow. The copy fail exploits the overflow bug caused by mishandling in-place optimization in the algif_aead kernel module . The POC demonstrates that it can splice to read-only page cache, make it writable (because in-place ops must be read/write) . So, when load a … Continue reading Copy Fail→
I recently wanted to learn about MCP (Model Context Protocol). As someone whose default programming language is Common Lisp, I naturally decided to build an MCP server using Lisp.
Thanks to the creators of 40ants-mcp, the library provides a nice pattern and code structure that I really like. However, I struggled significantly with installation and getting started. What should have taken minutes ended up taking days.
I'm sharing my experience here so that others who want to build MCP servers in Common Lisp can get started in minutes, not days like I did.
Prerequisites
Before you begin, make sure you have the following installed:
SBCL - A high-performance Common Lisp compiler
Roswell - A Common Lisp implementation manager and script runner
Quicklisp - The de facto package manager for Common Lisp
Ultralisp - A community-driven distribution of Common Lisp libraries
Installing Ultralisp
In SBCL with Quicklisp, you can enable Ultralisp by:
Building MCP servers with Common Lisp is straightforward once you know the tricks. The 40ants-mcp library is well-designed, and the OpenRPC integration works smoothly.
I hope this guide saves you the days of frustration I experienced. Happy hacking!
The full source code for this example is available at mcp-exper.
In Python development, we often default to using basic data structures like dict and list to move data around. They are flexible, JSON-compatible, and require no special setup. With the recent advancements in TypedDict and Annotated, the Python type system has become powerful enough to describe these structures with high precision.
baredtype is a library built to bridge the gap between these native structures and formal validation. It allows you to enforce strict rules on your data without ever forcing that data to change its shape or type.
The Strength of Basic Data Structures
The main draw of baredtype is that it works directly with the data structures you already use. There is no custom class instantiation or "wrapping" of data into library-specific objects.
Serialization and Deserialization
Because your data remains a standard list or dict, you don't need special methods to get your data in or out of a system. You use the standard tools you already know:
To JSON:json.dumps(my_data)
From JSON:json.loads(input_string)
Validation:validate(MySchema, my_data)
Handling Keys and None Values
Working with native structures means using standard Python idioms. baredtype respects TypedDict definitions for required fields and Annotated for value constraints, allowing you to handle None values and missing keys naturally.
fromtyping_extensionsimportTypedDict,NotRequired,AnnotatedfrombaredtypeimportvalidateclassUserData(TypedDict):username:stremail:Annotated[str|None,{"pattern":r"^[\w.-]+@[\w.-]+\.\w+$"}]age:NotRequired[int]# Use standard Python to check your data:
data={"username":"tech_lead","email":None}ifdata.get("email")isNone:print("No email provided.")if"age"notindata:print("Age is an optional key.")# Validation checks the types and the constraints
is_valid=validate(UserData,data)
Mapping to JSON Schema and OpenAPI
A core objective of baredtype is making it easy to map Python types to external standards like JSON Schema and OpenAPI. It handles the "quantifiers" that define how different types can be combined.
Quantifier Logic
oneOf: By using Annotated metadata, you can specify that data must match exactly one type in a Union. This is crucial for precise API definitions where ambiguity can lead to bugs.
allOf: This is naturally supported through TypedDict inheritance. When one TypedDict inherits from others, baredtype generates a schema representing the union of those requirements, staying consistent with OpenAPI standards.
Two Ways to Verify the Spec
When we define our data structures, we are writing a specification for our code. There are two primary ways to ensure our code follows this spec, both of which are supported by baredtype.
1. Static Type Checking
Because the library is built on TypedDict, you get the full benefit of tools like Mypy or Pyright. Your IDE can catch missing keys or type mismatches while you are writing the code. This finds errors before the code ever runs.
2. Property-Based Checking
While static types prove what should happen, property-based checking proves what can happen under stress. baredtype integrates with Hypothesis to automatically generate data that fits your TypedDict definitions, including constraints like min_length or regex patterns.
frombaredtypeimportgiven_from_annotations@given_from_annotationsdeftest_process_payload(payload:UserData):# Hypothesis generates a wide variety of valid UserData dicts
# to find edge cases in your logic.
result=my_function(payload)assertresultisnotNone
Validation: The Constant Requirement
Regardless of whether you use static checking, property-based checking, or both, runtime validation is a must. External data is inherently untrusted. Static checking verifies your internal logic, and property-based testing verifies your code's resilience during development. At the moment data enters your system, baredtype provides the final, essential check to ensure the data actually matches your specification.
Explore the Project
baredtype offers a lightweight validation layer that stays out of your data's way, leveraging the emerging strengths of the Python type system.
I reviewed the file and directory structure of several web-based free software projects released in 2003–2004: the Koha 1.2.0 library management system, the MRBS 1.2.1 meeting room booking system, and the DSpace 1.2 content repository system. These were written in Perl, PHP, and Java, respectively.
Endpoint files are named using an action, optionally followed by an entity, following patterns such as search.pl, search.php, SimpleSearchServlet.java, updatebibitem.pl, edit_entry.php, and EditProfileServlet.java. These verbs or verb phrases may or may not align with user workflows. For example, Koha includes opac_reserve.pl, indicating it handles the reservation workflow via the Online Public Access Catalog (OPAC) API. However, there is no dedicated "borrow" endpoint file.
Each system is designed in a modular style. Koha has a Borrower.pm module that provides a reserveslist function; MRBS uses functions.inc with functions such as make_room_select_html; and DSpace's Item.java includes methods like findAll. That said, they do not strictly follow a multi-tier architecture, for instance, database queries are not isolated into a dedicated data access layer. Still, DSpace, by using Servlets and JSPs, does establish a distinct presentation layer.
Because of the verb-based naming convention, files emphasize what they do rather than which architectural layer they belong to. This makes their purpose easy to understand at a glance.
However, this approach can make organization and testing more challenging. Logic, database queries, and presentation code are often mixed; sometimes not even separated into distinct functions.
In the context of programming in the 1980s, "global variables" likely brings to mind languages like MBASIC. However, using MBASIC as an example today would be challenging, as it is now rarely used or known. Instead, GNU Bash, which is the default shell scripting language for many systems—will be used to illustrate what global variables were traditionally like. Anyway, some might think of Fortran II, but I'm not familiar with it.
Bash Example
I wrote a Bash script consisting of four files:
a.bash
a.bash orchestrates everything. "Orchestration" might be too grand a word for these toy scripts, but I want to convey that it performs a role similar to Apache Airflow.
In the Python version, inc must refer to the module d to access the variable. Alternatively, counter could be explicitly imported.
importddefinc():d.counter+=1
c.py
Similarly, print_count in Python must also refer to module d.
importddefprint_count():print(d.counter)
d.py
Unlike in Bash, initializing a global variable from within a function—even in the same module—requires an explicit global declaration.
definit():globalcountercounter=1
Key Differences
As you can see, a global variable in Bash is truly global across files. In Python, however, a global variable is only global within its module, i.e., file. Furthermore, mutating a global variable in Bash requires no special syntax, whereas in Python a function must explicitly declare global to modify a module-level variable.
Consequently, although both are called "global variables," Python's are scoped to the module. This means they won’t interfere with variables in other modules unless we deliberately make them do so. For developers who use one class per module, a Python global variable behaves much like a class variable. Additionally, variable assignment inside a Python function is local by default, preventing accidental modification of global state unless explicitly intended.
In short, many traditional precautions about global variables in languages like Bash or MBASIC no longer apply in Python. Therefore, we might reconsider automatically rejecting global variables based on past advice and instead evaluate their use case thoughtfully.
I was impressed by pkgsrc because it is a powerful package management system that defines packages using a common tool like a Makefile. I later discovered that the PKGBUILD file is even more impressive, as its purpose is immediately clear. I initially attributed this to my greater familiarity with Bash scripting compared to Makefiles, but I now believe the true reason is PKGBUILD's level of abstraction.
It retains explicit calls to configure and make, preserving the transparency of a manual installation. This demonstrates that while increased abstraction can make code shorter, it can also hinder understanding.
Another potential advantage of greater abstraction is the ability to change the configure command for every package by modifying just one location. However, since GNU Autotools has continued to use the configure command for decades, it may not be worth sacrificing clarity for this particular benefit.
Expanding Emacs functionality is as simple as defining a new function instead of creating an entire extension package, as is often done in many other extensible editors. This function can then be re-evaluated, tested, and modified entirely within Emacs using just a few clicks or keyboard shortcuts, with no need to restart or reload Emacs.
An actively-maintained-implementation, long-term-stable-specification programming language
There are many programming languages that don't change much, including
Common Lisp, but Common Lisp implementations continue to be developed.
For example, SBCL (Steel Bank Common Lisp) released its latest version
just last month.
Common Lisp can be extended through libraries. For example, cl-interpol
enables Perl-style strings to Common Lisp without requiring a new
version of Common Lisp. cl-arrows allows Common Lisp to create pipelines
using Clojure-style syntax without needing to update the Common Lisp
specification. This exceptional extensibility stems from macro and
particularly reader macro support in Common Lisp.
Feature-packed
Common Lisp includes many features found in modern programming
languages, such as:
Garbage collection
Built-in data structures (e.g., vectors, hash tables)
Type hints
Class definitions
A syntactic structure similar to list comprehensions
Multi-paradigm
While Lisp is commonly associated with functional programming, Common
Lisp doesn't enforce this paradigm. It fully supports imperative
programming (like Pascal), and its object-oriented programming system
even includes advanced features. Best of all, you can freely mix all
these styles. Common Lisp even embraces goto-like code via TAGBODY-GO.
Performance
Common Lisp has many implementations, and some of them, such as SBCL,
are compilers that can generate efficient code.
With some (of course, not all) implementations, many programs written in
dynamic programming languages run slower than those in static ones, such
as C and Modula-2.
First, an example of the generated assembly will be shown, along with
more explanation about why it might be slowed down by some dynamic
implementations
The code listing below is a part of a program written in Modula-2, which
must be easy to read by programmers of languages in the extended ALGOL
family.
TYPE
Book = RECORD
title: ARRAY[1..64] OF CHAR;
price: REAL;
END;
PROCEDURE SumPrice(a, b: Book): REAL;
BEGIN
RETURN a.price + b.price;
END SumPrice;
The code is mainly for summing the price of books, and only the part
'a.price + b.price' will be focused on.
'a.price + b.price' is translated into X86-64 assembly code list below
using the GNU Modula-2 compiler.
"movsd 80(%rbp), %xmm1' and 'movsd 152(%rbp), %xmm0' are for loading
'prices' to registers '%xmm1' and '%xmm0', respectively. Finally, 'addsd
%xmm1, %xmm0' is for adding prices together. As can be seen, the prices
are loaded from exact locations relative to the value of the '%rbp'
register, which is one of the most efficient ways to load data from
memory. The instruction 'addsd' is used because prices in this program
are REAL (floating point numbers), and '%xmm0', '%xmm1', and 'movsd' are
used for the same reason. This generated code should be reasonably
efficient. However, the compiler needs to know the type and location of
the prices beforehand to choose the proper instructions and registers to
use.
In dynamic languages, 'SumPrice' can be applied to a price whose type is
an INTEGER instead of a REAL, or it can even be a string/text. A
straightforward implementation would check the type of 'a' and 'b' at
runtime, which makes the program much less efficient. The checking and
especially branching can cost more time than adding the numbers
themselves. Moreover, obtaining the value of the price attribute from
'a' and 'b' might be done by accessing a hash table instead of directly
loading the value from memory. Of course, while a hash-table has many
advantages, it's less efficient because it requires many steps,
including comparing the attribute name and generating a hash value.
However, compilers for dynamic languages can be much more advanced than
what's mentioned above, and SBCL is one such advanced compiler. SBCL can
infer types from the code, especially from literals. Moreover, with
information from type hints and 'struct' usage, SBCL can generate code
that's comparably as efficient as static language compilers.
The assembly code format is slightly different from the one generated by
the GNU Modula-2 compiler, but the main parts, the 'MOVSD' and 'ADDSD'
instructions and the use of XMM registers—are exactly the same. This
shows that we can write efficient code in Common Lisp at least for this
case. This shows that we can write efficient code in Common Lisp, at
least in this case, that is as efficient as, or nearly as efficient as,
a static language.
This implies that Common Lisp is good both for high-level rapid
development and optimized code, which has two advantages: (1) in many
cases, there is no need to switch between two languages, i.e., a
high-level one and a fast one; (2) the code can be started from
high-level and optimized in the same code after a profiler finds
critical parts. This paradigm can prevent premature optimization.
Interactive programming
Interactive programming may not sound familiar. However, it is a common
technique that has been used for decades. For example, a database engine
such as PostgreSQL doesn't need to be stopped and restarted just to run
a new SQL statement. Similarly, it is akin to a spreadsheet like Lotus
1-2-3 or Microsoft Excel, which can run a new formula without needing to
reload existing sheets or restart the program.
Common Lisp is exceptionally well-suited for interactive programming
because of (1) integrated editors with a REPL (Read Eval Print Loop),
(2) the language's syntax, and (3) the active community that has
developed libraries specifically designed to support interactive
programming.
Integrated editors with a REPL
With an integrated with a REPL, any part of the code can be evaluated
immediately without copying and pasting from an editor into a REPL. This
workflow provides feedback even faster than hot reloading because the
code can be evaluated and its results seen instantaneously, even before
it is saved. There are many supported editors, such as Visual Studio
Code, Emacs, Neovim, and others.
the language's syntax
Instead of marking region arbitrarily for evaluating, which is not very
convenient when it is done every few seconds, in Common Lisp, we can
mark a form (which is similar to a block in ALGOL) by moving a cursor to
one of the parentheses in the code, which is very easy with structural
editing, which will be discussed in the next section.
Moreover, even a method definition can be evaluated immediately without
resetting the state of the object in Common Lisp. Since method
definitions are not nested in defclass, this allows mixing interactive
programming and object-oriented programming (OOP) smoothly.
According to the code listing above, the method 'update-i' can be
redefined without interfering with the pre-existing value of 'i'.
Structural editing
Instead of editing Lisp code like normal text, tree-based operations can
be used instead, such as paredit-join-sexps and
paredit-forward-slurp-sexp. Moving cursor operations, such as
paredit-forward, which moves the cursor to the end of the form (a
block). These structural moving operations are also useful for selecting
regions to be evaluated in a REPL.
Conclusion
In brief, Common Lisp has unparalleled combined advantages, which are
relevant to software development especially now, not just an archaic
technology that just came earlier. For example, Forth has a
long-term-stable specification, and works well with interactive
programming, but it is not designed for defining classes and adding type
hints. Julia has similar performance optimization and OOP is even
richer, but it doesn't have a long-term-stable specification. Moreover,
Common Lisp's community is still active, as libraries, apps, and even
implementations continue to receive updates.
2018-01-19 Information and documentation - Transliteration of scripts in use in Thailand - Part 1: Transliteration of Akson-Thai-Noi — TC46 / WG3 (WG2 N4927A, L2/18-042)
2018-01-19 Results on ISO CD 20674-1: Information and documentation - Transliteration of scripts in use in Thailand - Part 1: Transliteration of Akson-Thai-Noi — TC46 Secretatriat (WG2 N4927B, L2/18-043)
2018-02-20 Thai-Noi Transliteration — Martin Hosken (WG2 N4939, L2/18-068)
เป็นความเห็นจากคุณ Martin Hosken ผู้เชี่ยวชาญจาก SIL โดยสรุปเห็นว่าอักษรไทยน้อยเข้ากันได้กับอักษรธรรมมากกว่าอักษรไทย
2018-02-28 Towards a comprehensive proposal for Thai Noi / Lao Buhan script — Ben Mitchell (L2/18-072)
เป็นความเห็นจากคุณ Ben Mitchell ผู้เชี่ยวชาญอีกท่านหนึ่ง โดยมีผู้ร่วมให้ข้อมูลคือ Patrick Chew, ผมเอง และ อ.ประพันธ์ เอี่ยมวิริยะกุล โดยสรุปเห็นว่าควรเพิ่มอักขระไทยน้อยในบล็อคอักษรลาว โดยเพิ่มเติมจากอักษรลาวบาลีของพุทธบัณฑิตสภาอีกที และได้เสนอทางเลือกต่างๆ ดังที่ผมได้สรุปไว้ แต่ยังไม่ระบุว่าจะเลือกวิธีการไหน
Recommendations to UTC #155 April-May 2018 on Script Proposals (L2/18-168) (อยู่ที่ข้อ 6.) และบันทึกการประชุมของ UTC #155 (L2/18-115) (อยู่ที่ข้อ D.8.1 และ D.8.3)
สรุปข้อแนะนำของคณะกรรมการว่าอักษรไทยน้อยไม่ใข่ส่วนขยายของอักษรไทย และผู้เสนอร่างอักษรไทยน้อย (หมายถึง อ.นิตยา กาญจนวรรณ จากราชบัณฑิตยสภา) ควรนำข้อมูลในเอกสารของคุณ Ben Mitchell ข้างต้นไปใช้ประกอบการร่างด้วย โดยมอบให้ Deborah Anderson ร่างเอกสารแจ้งเจ้าของร่าง ซึ่งก็คือเอกสาร L2/18-070
No one actually cares about my programming environment journey, but I’ve often been asked to share it, perhaps for the sake of social media algorithms. I post it here, so later, I can copy and paste this conveniently.
My first computer, in the sense that I, not someone else, made the decision to buy it, ran Debian in 2002. It was a used Compaq desktop with a Pentium II processor, which I bought from Zeer Rangsit, a used computer market that may be the most famous in Thailand these days. When I got it home, I installed Debian right away. Before I bought my computer, I had used MBasic, mainly MS-DOS, Windows 3.1 (though rarely), and Solaris (remotely). For experimentation, I used Xenix, AIX, and one on DEC PDP-11 that I forgot.
Since I started with MBasic, that was my first programming environment. I learned Logo at a summer camp, so that became my second. Later, my father bought me a copy of Turbo Basic, and at school, I switched to Turbo Pascal.
After moving to GNU/Linux, I used more editors instead IDEs. From 1995 to 2010, my editors were pico, nvi, vim, TextMate, and Emacs paired with GCC (mostly C, not C++), PHP, Perl, Ruby, Python, JavaScript, and SQL. I also used VisualAge to learn Java in the 90s. I tried Haskell, OCaml, Objective C, Lua, Julia, and Scala too, but it was strictly for learning only.
After 2010, I used IntelliJ IDEA and Eclipse for Java and Kotlin. For Rust (instead of C), I used Emacs and Visual Studio Code. I explored Racket for learning purposes, then later started coding seriously in Clojure and Common Lisp. I tried using Vim 9.x and Neovim too, they were great, but not quite my cup of tea.
In 2025, a few days ago, I learned Smalltalk with Pharo to deepen my understanding of OOP and exploratory programming.
Update 2025/07/20: I forgot to mention xBase. In the '90s, I used it in a programming competition, but none of my programs in xBase reach production.
จาก blog ที่แล้ว ผมได้เล่าถึงการรองรับอักษรธรรมในปัจจุบันที่ text shaping engine ต่างๆ หันมาใช้ Universal Shaping Engine (USE) ตามข้อกำหนดของไมโครซอฟท์ โดย USE เองเป็น engine ครอบจักรวาลที่มีการจัดการภายในตามคุณสมบัติของอักขระ Unicode เช่น การสลับสระหน้ากับพยัญชนะต้นสำหรับอักษรตระกูลพราหมี และเรียกใช้ OpenType feature ต่างๆ ในฟอนต์ตามลำดับที่กำหนดไว้
และการจัดการภายในของ USE ก็ทำให้มีข้อเสนอที่จะปรับโครงสร้างการลงรหัสข้อความอักษรธรรมเพื่อให้ทำงานกับ USE ได้ แต่มันก็ยังไม่เข้าที่เข้าทางนัก จึงเกิดแนวคิดที่จะหลบเลี่ยง USE แล้วทำทุกอย่างเองในฟอนต์ แต่ไปติดปัญหาที่ MS Word ที่ไม่ยอมให้หลบได้ง่ายๆ ทำให้เราอยู่บนทางแยกที่ต้องเลือกว่าจะใช้ USE ที่ยังไม่เข้าที่ หรือจะเลี่ยง USE ไปทำทุกอย่างเองโดยทิ้ง MS Word ไว้ข้างหลัง
blog นี้ก็จะวิเคราะห์ต่อ ว่าทางเลือกแต่ละทางมีข้อดีข้อเสียอย่างไร
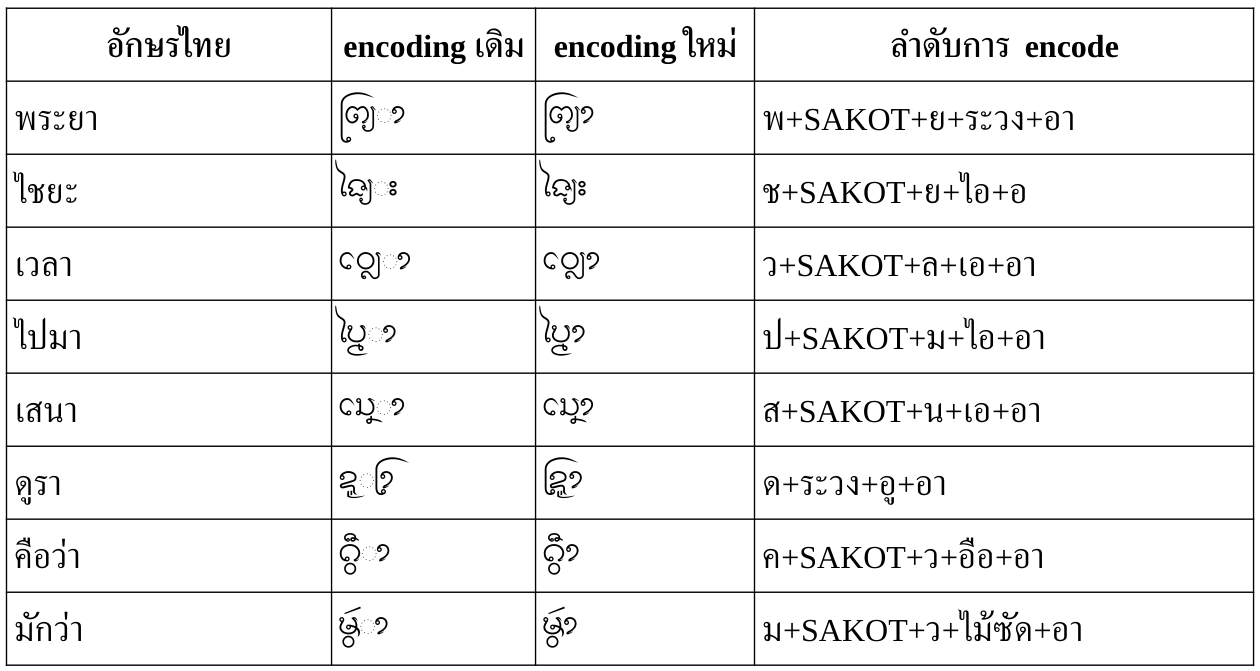
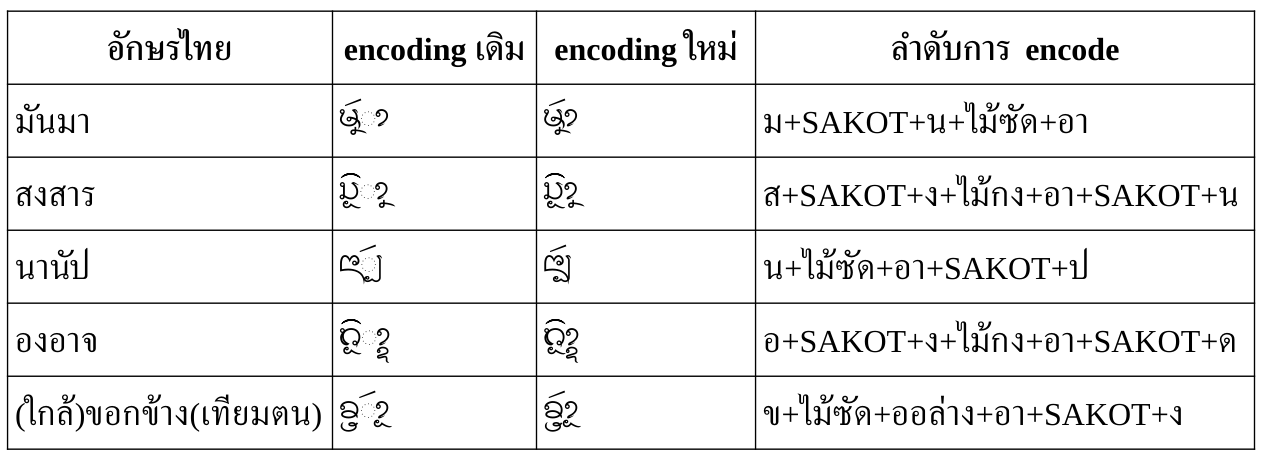
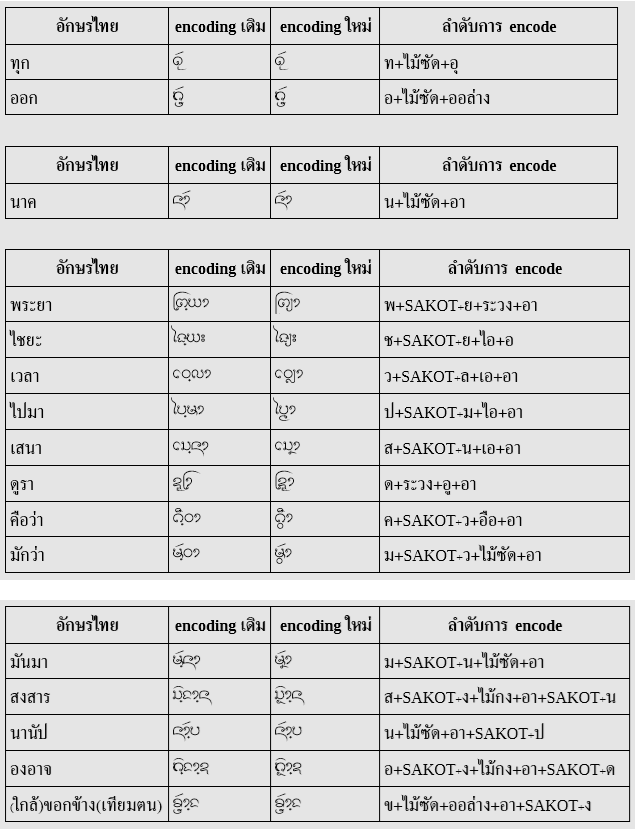
Encoding แบบใหม่
ตามข้อเสนอในเอกสาร Structuring Tai Tham Unicode เมื่อตัดรายละเอียดที่อักษรธรรมลาว/อีสานไม่ใช้ออกไป ก็พอจะสรุปลำดับอักขระในข้อความได้เป็น:
S ::= CC (Vs | Vf)?
โดยที่ CC คือ consonant cluster พร้อมสระหน้า/ล่าง/บน วรรณยุกต์ สระหรือตัวสะกดปิดท้าย
CC ::= C M? V? T? F?
C ::= [<ก>-<ฮ><อิลอย>-<โอลอย><แล><ส_สองห้อง><ตัวเลข>] | <ห><SAKOT>[<ก>-<ม>]
M ::= <ระวง>? <ล_ล่าง>? (<SAKOT><ว>)? (<SAKOT><ย>)?
V ::= Vp? Vb? Va?
Vp ::= [<เอ>-<ไม้ม้วน>] // สระหน้า
Vb ::= [<อุ>-<อู><ออ_ล่าง>] // สระล่าง
Va ::= [<อิ>-<อือ><ไม้กง><ไม้เก๋าห่อนึ่ง>][<ไม้ซัด><ไม้กั๋ง>]? // สระบน
T ::= [<ไม้เอก>-<ไม้โท>]
F ::= Fs? [<ละทั้งหลาย><ไม้กั๋งไหล><ง_บน><ม_ล่าง><บ_ล่าง><ส_ล่าง><ไม้กั๋ง>]? (<SAKOT> S)?
Fs ::= [<อ><ส_สองห้อง><ออย>] | <SAKOT>[<ก>-<ฬ>] // อ ของสระเอือ หรือ ตัวสะกด
สังเกตว่ามี recursion ใน F เพื่อแทนลูกโซ่ของพยางค์ในคำบาลีด้วย
ต่อจาก CC ก็จะตามด้วยสระกินที่ (spacing vowels) ซึ่งแบ่งเป็นสระมีตัวสะกด (Vs) และสระไม่มีตัวสะกด (Vf)
แม้ encoding แบบใหม่ที่เสนอมีจุดมุ่งหมายเพื่อให้วาดแสดงด้วย USE แต่เมื่อลองใช้กับ USE จริงกลับยังมี dotted circle เกิดขึ้นในหลายกรณี ซึ่งจากการทดลองก็พอจะสังเกตลักษณะของ USE ที่ต่างจากโครงสร้างที่เสนอในร่างดังนี้:
ลำดับสระใน V สระบนมาก่อนสระล่าง ไม่ใช่ตามหลังสระล่างอย่างในร่างฯ ดังนั้นจึงอาจปรับกฎเป็น:
V ::= Vp? Va? Vb?
วรรณยุกต์อยู่หน้าสระกินที่ไม่ได้ แต่ตามหลังได้ และต้องอยู่ก่อนตัวสะกด ดูเหมือน USE จะนับ Vs เป็นส่วนหนึ่งของ V:
V ::= Vp? Va? Vb? Vs?
ซึ่งถ้าเป็นเช่นนั้น ก็หมายความว่า USE ก็ยังต้องการการ reorder ให้วรรณยุกต์ไปอยู่ในตำแหน่งก่อนหน้าสระกินที่เพื่อให้สามารถซ้อนบนพยัญชนะได้ด้วย มันจะกลายเป็นความซับซ้อนเกินจำเป็นน่ะสิ
หลักการสำหรับการป้อนข้อความ
สมมติว่าเราใช้ encoding แบบ USE เราจะมีหลักในใจอย่างไร? เราจะใช้ลำดับการพิมพ์แบบที่เราเคยใช้กับอักษรไทยไม่ได้อีกแล้ว เพราะมันคือการ encode แบบกึ่ง visual ไม่ว่าเขาจะยืนยันที่จะเรียกว่า logical order ยังไงก็ตาม แต่ลำดับการ encode นี้จะไม่ตรงกับลำดับการสะกดคำเสมอไป มันเน้นให้เรียงพิมพ์ได้เป็นหลัก! โดยมีลำดับแบบที่เรียกว่า logical order มาหลอกให้งงเล่น
การเขียนอักษรธรรมในหลายกรณีมีการใช้ตัวห้อย/ตัวเฟื้องเป็นพยัญชนะต้นของพยางค์ถัดไป แทนที่จะใช้ตัวเต็ม ซึ่งในกรณีเหล่านี้ ถ้าวางตัวห้อย/ตัวเฟื้องในตำแหน่งของตัวสะกด ก็จะไม่สามารถวางสระต่อได้อีก เพราะดูเหมือน USE ไม่ได้รองรับ recursion ใน F ตามกฎในร่างฯ และเมื่อแจงต่อไป CC ของพยางค์ถัดไปก็ขาดพยัญชนะต้นตัวเต็ม (C) มาขึ้นต้น CC แต่ถ้า encode โดยเลี่ยงให้ตัวห้อย/ตัวเฟื้องดังกล่าวเป็นส่วนหนึ่งของ CC ของพยางค์ก่อนหน้าก็จะสามารถวางสระต่อได้ แต่ลำดับก็จะดูขัดสามัญสำนึกสักหน่อย
จึงพอสรุปได้ว่ายังมีความแตกต่างระหว่างข้อกำหนดในร่างฯ กับสิ่งที่ USE รองรับจริง ทำให้ไม่ว่าจะพยายามอย่างไรก็จะมีข้อบกพร่องเกิดขึ้นเสมอ และแอปที่มีปัญหาเสมอๆ ก็คือ MS Word
หากเลือกใช้ข้อกำหนด USE ทุกแอปที่รองรับ USE ก็จะได้การรองรับแบบ เกือบๆ ครบถ้วน (โดย MS Word จะมีปัญหามากกว่าเพื่อนสักหน่อย) โดยแลกกับลำดับการ encode ที่ผิดธรรมชาติของผู้ใช้ ซึ่งเป็นการแลกที่ผมคิดว่าไม่คุ้ม เพราะจะมีผลให้เกิดเอกสารที่ encode แปลกๆ เกิดขึ้นในระหว่างที่ USE ยังไม่พร้อม แถมสิ่งที่ได้คืนมาก็ยังไม่ใช่สิ่งที่สมบูรณ์เสียด้วย
ในขณะที่หากเลือกหลีกเลี่ยง USE แอปส่วนใหญ่ยกเว้น MS Word ก็จะสามารถจัดแสดงอักษรธรรมได้สมบูรณ์ (ดังกล่าวไว้ใน blog ที่แล้ว) โดยที่ผู้ใช้ก็ยังคงใช้ encoding แบบเก่าได้เช่นเดิม และเมื่อไรที่ USE พร้อม ก็เพียงแปลง encoding ไปเป็นแบบใหม่ (ซึ่งอาจจะอัตโนมัติหรือ manual ก็ค่อยว่ากัน) โดยไม่ต้องมี encoding ชั่วคราวของ USE มาแทรกกลางเป็นชนิดที่สามให้เกิดความสับสนเพิ่ม โดยแลกกับการทิ้ง MS Word ที่ยังไงก็ไม่สมบูรณ์อยู่แล้ว และแนะนำให้ผู้ใช้อักษรธรรมใช้ LibreOffice หรือ Notepad (ซึ่งเป็นผลพลอยได้) ในการเตรียมเอกสารแทน ส่วนเว็บเบราว์เซอร์นั้นไม่เป็นปัญหา เพราะเบราว์เซอร์ส่วนใหญ่ก็ใช้ Harfbuzz เป็นฐานกันอยู่แล้ว การรองรับก็จะเหมือนๆ กับใน LibreOffice นั่นแล
ด้วยเหตุนี้ ผมจึงเลือกที่จะสร้างฟอนต์อักษรธรรมที่ หลีกเลี่ยง USE ต่อไป จนกว่า USE จะพร้อมจริงๆ
ซึ่งเมื่อไปตรวจสอบเอกสารที่เกี่ยวข้อง ก็พบเอกสาร Structuring Tai Tham Unicode (L2/19-365) โดย Martin Hosken ซึ่งเป็นร่างข้อเสนอที่จะปรับลำดับการลงรหัสอักขระอักษรธรรมจาก แบบเริ่มแรก (L2/05-095R) เพื่อการวาดแสดงด้วย USE ซึ่งลำดับแบบใหม่ค่อนข้างแตกต่างจากลำดับการสะกดในใจพอสมควร และข้อเสนอใหม่ก็ยังคงเป็นฉบับร่าง จึงเกิดความไม่แน่นอนว่าแนวทางการลงรหัสปัจจุบันจะเป็นแบบไหน
เนื่องจากพระอาจารย์ชยสิริ ชยสาโร ประสงค์จะให้ผมเพิ่มอักษรธรรมลงในฟอนต์ Laobuhan ของท่าน ผมจึงถือโอกาสทดลองทำตามข้อกำหนดของ USE อันใหม่เสียเลย โดยพยายามทดสอบบน Windows 11 ด้วย นอกเหนือจากที่เคยทดสอบเฉพาะบนลินุกซ์ โดยในข้อกำหนดใหม่ USE มีการ reorder สระหน้าให้ จึงไม่ต้องทำในฟอนต์เองอีกต่อไป สิ่งที่ควรทำ (เรียงตามลำดับการเรียกใช้โดย USE) จึงเป็น:
pref (Pre-base forms) เพื่อระบุตำแหน่งของระวง เพื่อที่ USE จะ reorder ไปไว้หน้าพยัญชนะต้นให้ในภายหลัง
อักษรธรรมบน LibreOffice Writer แบบใช้รหัสอักษร DFLT
อักษรธรรมบน Windows Notepad แบบใช้รหัสอักษร DFLT
แต่ข่าวร้ายคือ มันเละบน MS Word
อักษรธรรมบน MS Word แบบใช้รหัสอักษร DFLT
ซึ่งจากการทดลองก็สรุปได้ว่ามันเกิดจาก:
ข้อจำกัดของ ccmp บน engine ของ MS Word ที่ดูจะไม่รองรับ contextual substitution ที่ซับซ้อน (เข้าใจว่าทำได้แค่ multiple substitution และ ligature substitution อย่างง่ายเท่านั้น)
engine ของ MS Word ยังคงใช้ USE เช่นเดิม ทำให้ถึงแม้จะเปลี่ยนไปใช้ liga ที่สามารถทำ contextual substitution ซับซ้อนได้ ก็จะเกิดการ reorder สระหน้าซ้ำซ้อนกันระหว่างโดยตัว engine เองก้บโดยกฎในฟอนต์จนสระหน้าสามารถเลื่อนข้ามพยัญชนะไปได้ถึง 2 ตำแหน่ง
ถ้าคิดตามหลักเหตุผลแล้ว ถ้า ccmp ที่ USE เรียกใช้ในขั้น preprocessing สามารถทำงานได้อย่างถูกต้อง โดยให้กฎแทรก glyph ผีสักตัว (เช่น ZWNJ) ไว้หน้าสระหน้าที่สลับลำดับแล้ว เพื่อให้มันคั่นระหว่างสระหน้ากับพยัญชนะที่อยู่ก่อนหน้าไว้ ก็ควรจะสามารถป้องกัน USE ไม่ให้ reorder ซ้ำอีกได้ แต่ในเมื่อ DirectWrite engine ที่ MS Word ใช้ไม่รองรับ ccmp ที่ซับซ้อน (แบบที่ Harfbuzz ทำ) มันก็จบเห่ตั้งแต่ต้น ส่วน liga หรือ clig ที่รองรับ contextual substitution แบบซับซ้อนได้ ก็ถูกเรียกทำงานหลังการ reorder ภายในของ USE ไปแล้ว จึงไม่สามารถควบคุมอะไรได้ทันการณ์
ในเมื่อ USE ก็ไม่สมบูรณ์ จะเลี่ยง USE ก็ติดปัญหากับ MS Word ผมจึงอยู่บนทางเลือก:
ใช้ USE ไปเลย แล้วรอให้มีการแก้ปัญหาของ USE อีกที
เลี่ยง USE ต่อไป โดยได้การทำงานของไม้กั๋งไหลเพิ่มมาด้วย แต่ยอมทิ้งการรองรับบน MS Word
เลี่ยง USE แบบต้องปรับฟอนต์ขนานใหญ่ให้ใช้ ccmp ในการ reorder ให้ได้ ผ่าน ligature glyph แล้วค่อยรื้อกลับใหม่อีกทีเมื่อ USE พร้อม
แอปที่ใช้ Harfbuzz นั้นทำงานได้กับทุกทางเลือก ปัญหาอยู่ที่แอปนอกเหนือจากนั้น โดยในที่นี้คือ MS Word กับ Notepad ซึ่งเราต้องเลือกเอาอย่างใดอย่างหนึ่ง ถ้าใช้ USE ก็จะได้ MS Word ที่ทำงานได้เท่าที่ USE รองรับ ถ้าไม่ใช้ USE ก็จะได้ Notepad ที่ทำงานเต็มรูปแบบ
โดย Notepad เองก็ถือเป็นตัวแทนของแอปอื่นๆ ที่รองรับ OpenType แบบผิวเผินด้วย ในขณะที่ MS Word ก็น่าจะเป็นแอปหลักแอปหนึ่งที่ผู้ใช้ฟอนต์จะใช้เตรียมเอกสาร (แต่จะให้ดี LibreOffice เป็นทางเลือกที่เปิดกว้างต่อ solution ต่างๆ มากกว่า)
ผมจะวิเคราะห์ใน blog หน้าว่าจะพิจารณาชั่งน้ำหนักอย่างไรต่อไป
I've been told to avoid linked lists because their elements are scattered everywhere, which can be true in some cases. However, I wonder what happens in loops, which I use frequently. I tried to inspect memory addresses of list elements of these two programs run on SBCL.
In both programs, the list elements are not scattered. So, if scattered list elements were an issue for these simple cases, you probably used the wrong compiler or memory allocator.
“NO leap second will be introduced at the end of June 2025. The difference between Coordinated Universal Time UTC and the International Atomic Time TAI is : from 2017 January 1, 0h UTC, until further notice : UTC-TAI = -37 s” — IERS EOP Bulletin C#69















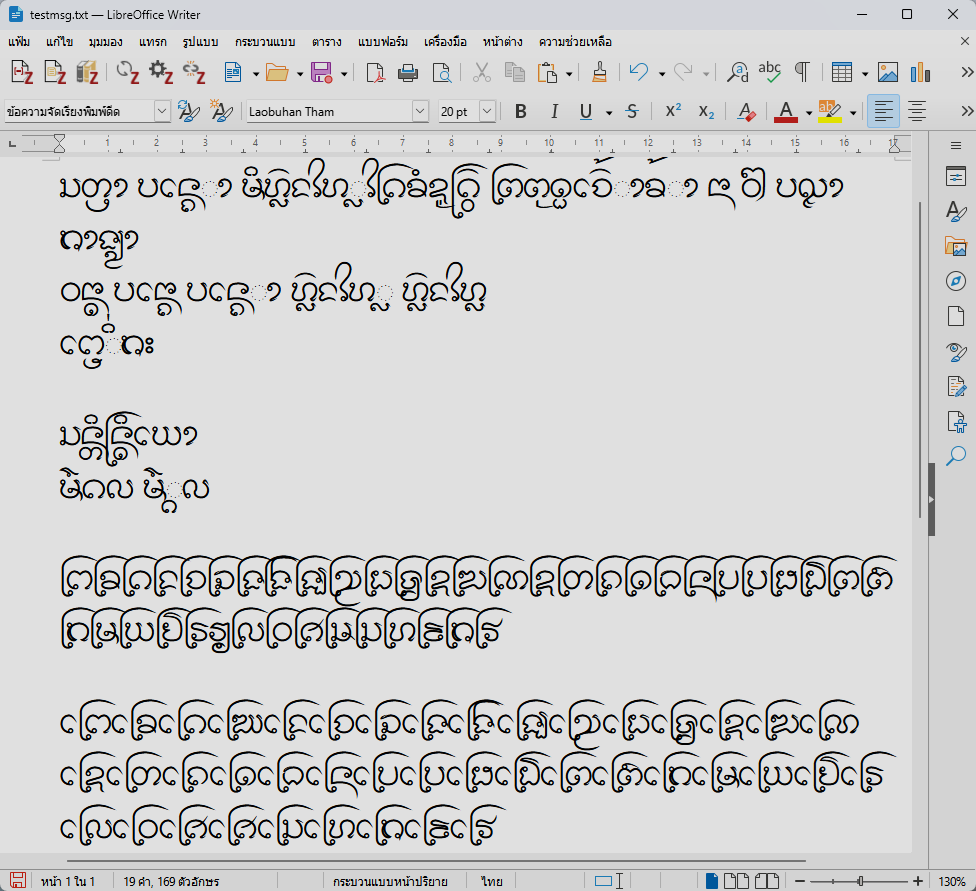 อักษรธรรมบน LibreOffice Writer แบบใช้ USE
อักษรธรรมบน LibreOffice Writer แบบใช้ USE
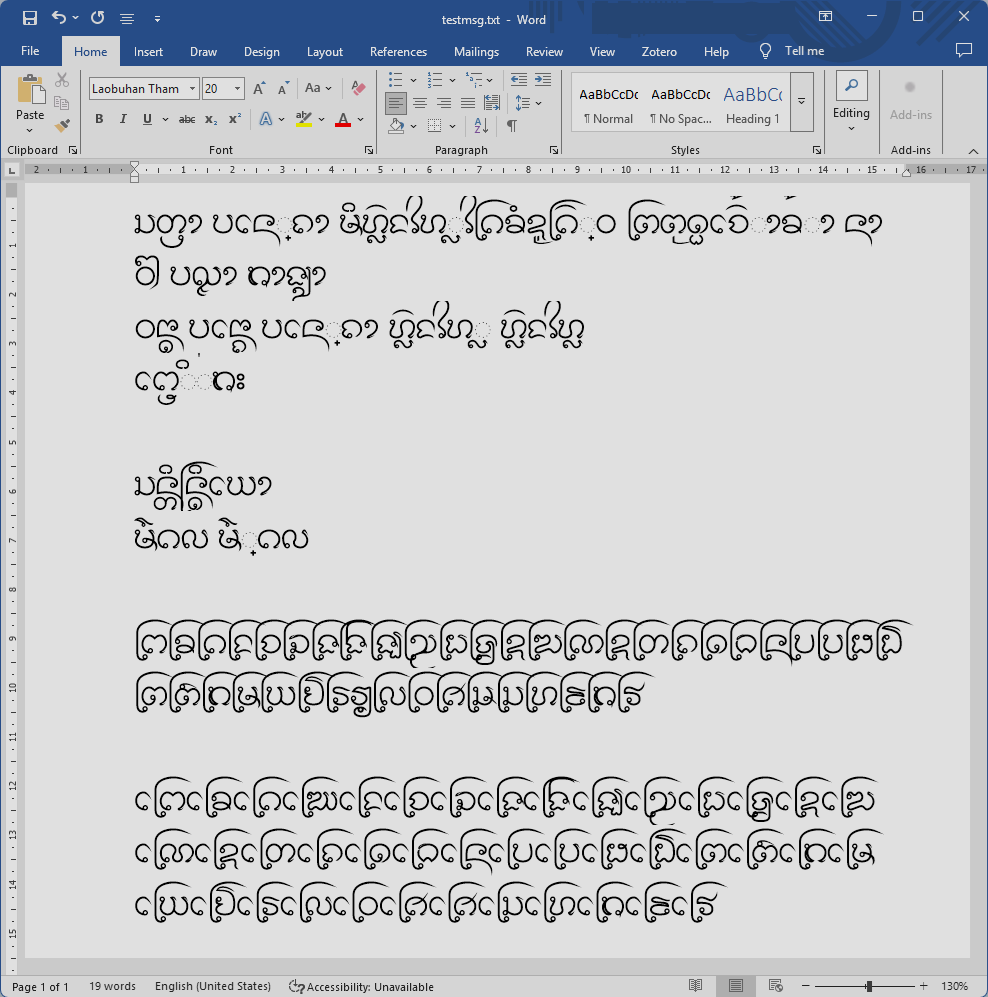 อักษรธรรมบน MS Word แบบใช้ USE
อักษรธรรมบน MS Word แบบใช้ USE
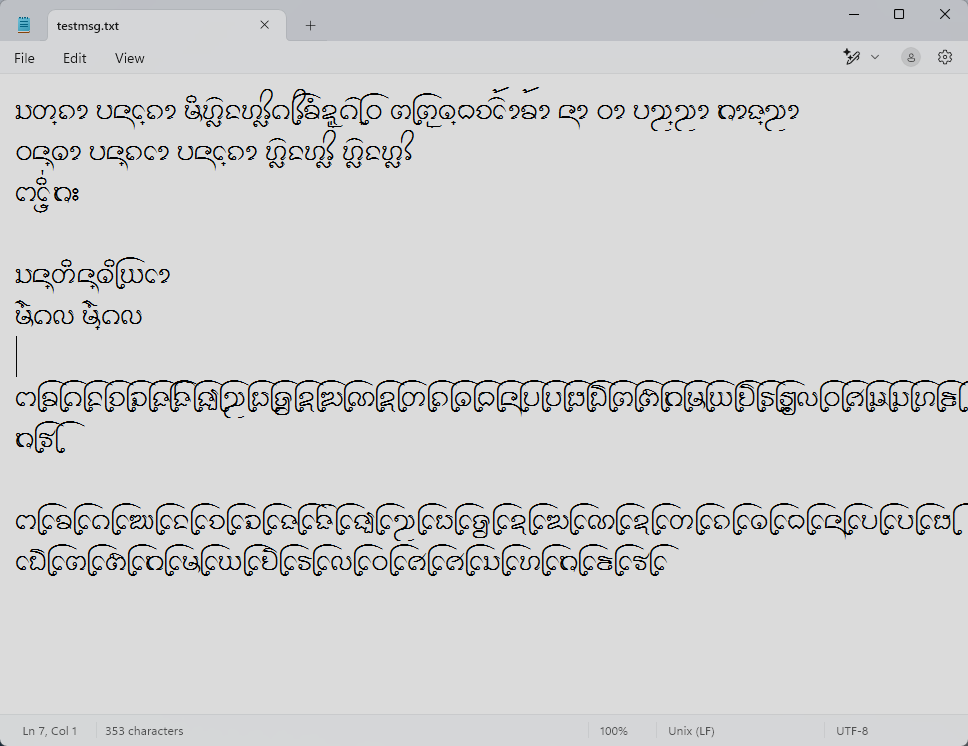 อักษรธรรมบน Windows Notepad แบบใช้ USE
อักษรธรรมบน Windows Notepad แบบใช้ USE
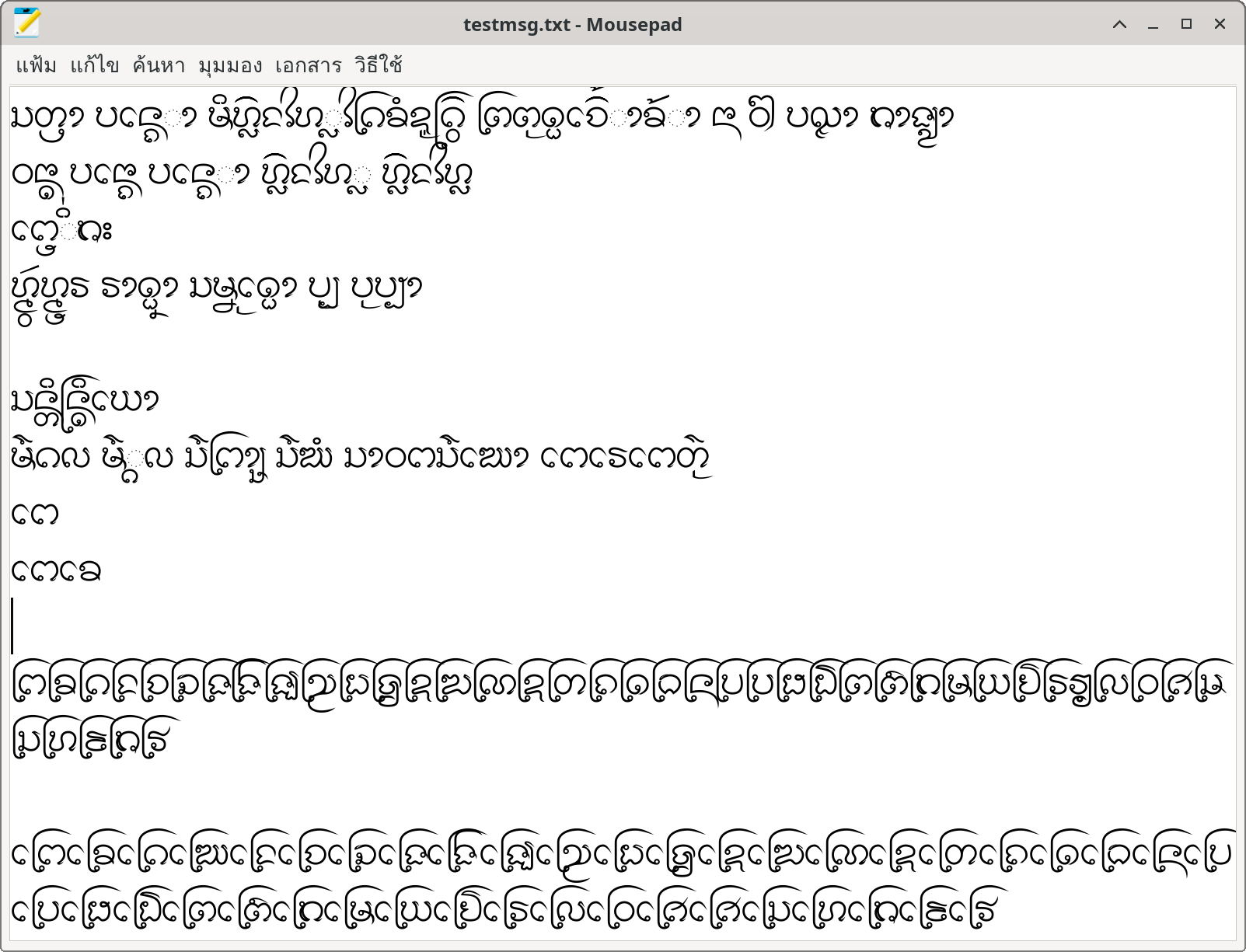 อักษรธรรมบน Linux Mousepad แบบใช้ USE
อักษรธรรมบน Linux Mousepad แบบใช้ USE
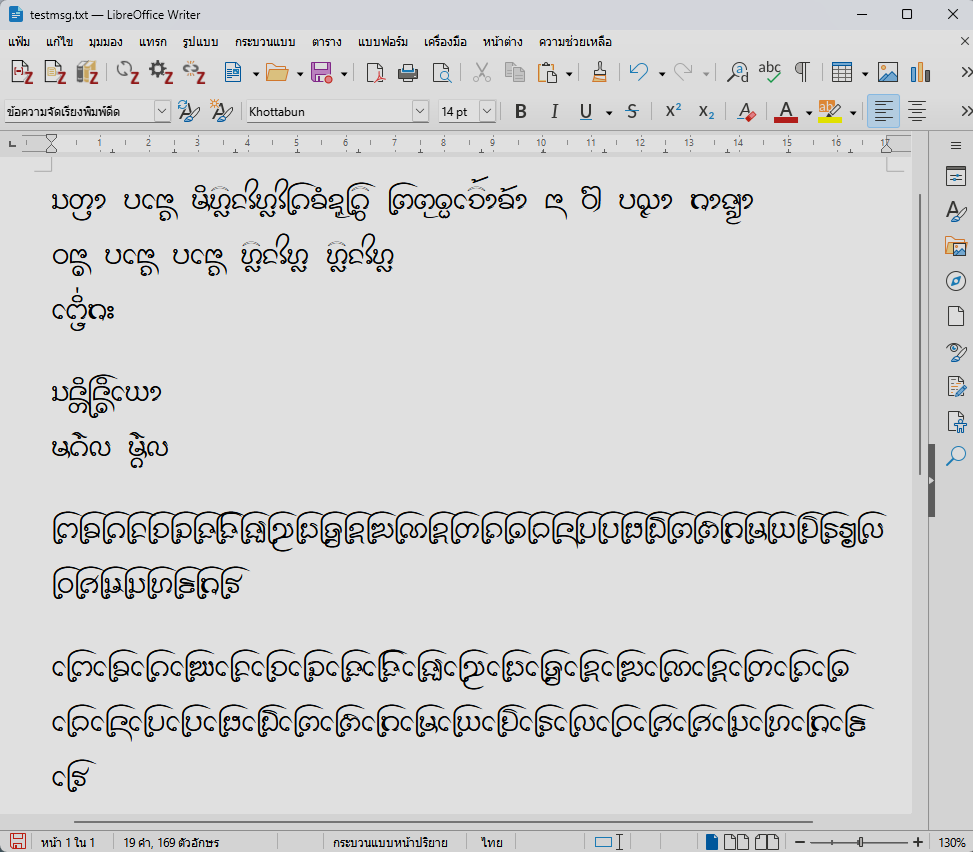 อักษรธรรมบน LibreOffice Writer แบบใช้รหัสอักษร
อักษรธรรมบน LibreOffice Writer แบบใช้รหัสอักษร 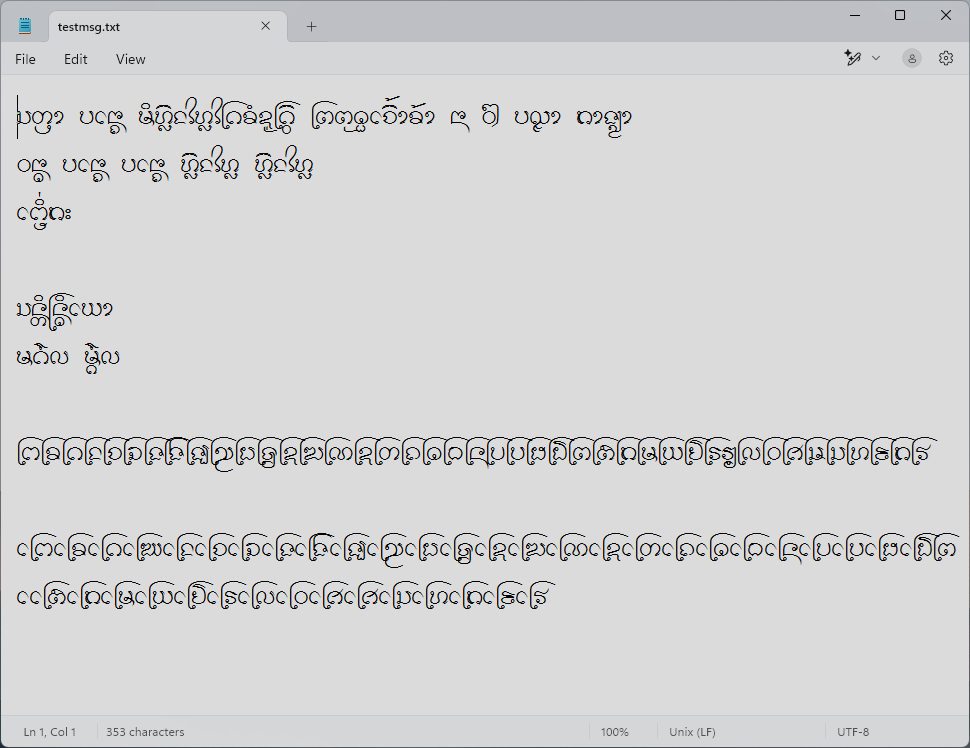 อักษรธรรมบน Windows Notepad แบบใช้รหัสอักษร
อักษรธรรมบน Windows Notepad แบบใช้รหัสอักษร 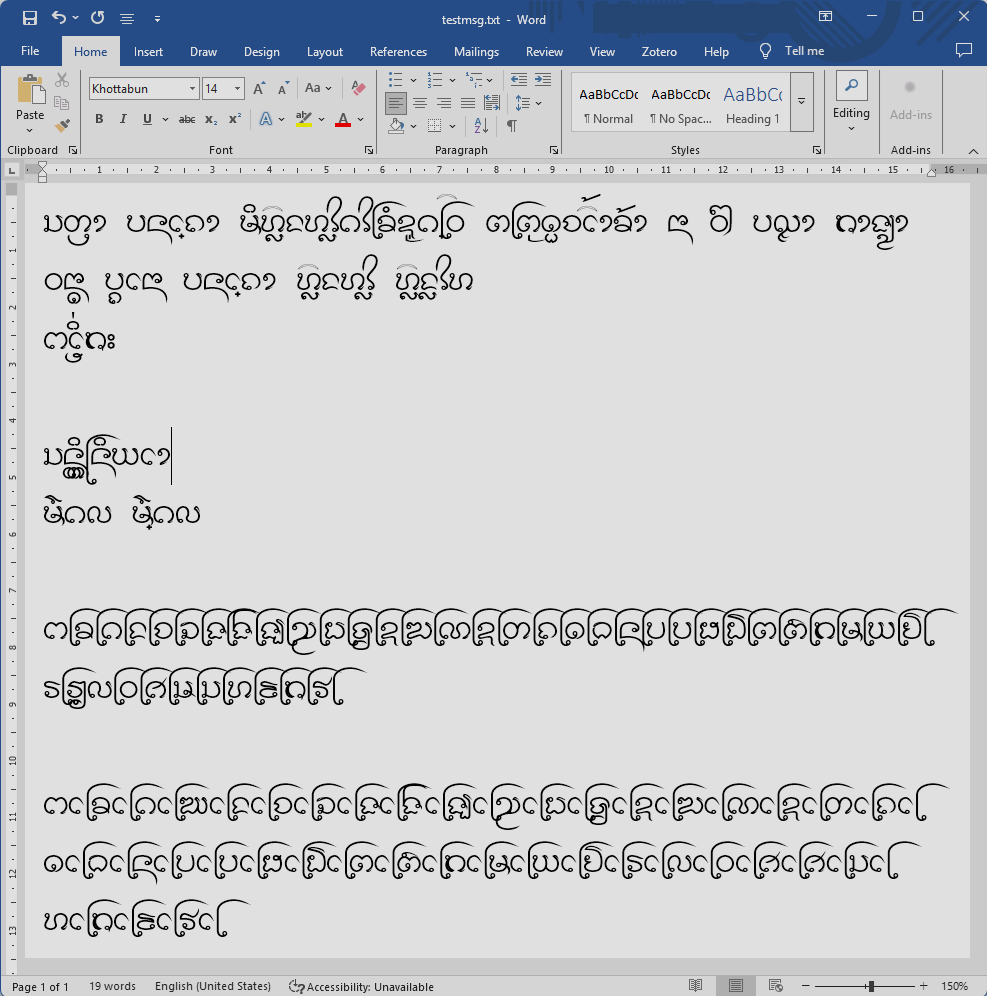 อักษรธรรมบน MS Word แบบใช้รหัสอักษร
อักษรธรรมบน MS Word แบบใช้รหัสอักษร