Always Shifted. Mai Kang Lai is strictly placed on the second consonant without exception. This seems to be traditional writing system.
It is practiced by Lao Tham and traditional Lanna.
- [Lao] ແບບຣຽນໄວ ເຫຼັ້ມສອງ ຣຽນອ່ານໝັງສືທັມ ຂຽນເປັນພາສາບາລີ by ພຼະຍາຫຼວງມະຫາເສນາ(ຜູຍ), Lao PDR., pp.28

- [Lao] ชุดความรู้ ๗ อักษรธรรมภาษาบาลี by วัฒน ศรีสว่าง, pp. 15

- [Lao] การสะกดคำอักษรตัวธรรม by อ.ยุทธพงศ์ มาตย์วิเศษ, pp. 24

- [Lao] บทสูดขวัญ manuscript, pp. 5/27

- [Lao] โวหารโพธิ manuscript, pp. 16/36

- [Lanna] ตำราเรียนหนังสือลานนาไทย by อ.มณี พยอมยงค์, Chiang Mai University, pp.81

- [Lanna]
หนังสือค่าวซอเรื่องจันทฆา พิมพ์เมื่อ พ.ศ.2480,
Illustration from การอ่านจารึกสมัยต่างๆ (Thai Palaeography) FL 344 by ศ.ธวัช ปุณโณทก, Ramkhamhaeng University, pp.162

- [Lanna] แบบเรียนอ่านและเขียน อักษรขอม อักษรธรรมลานนา อักษรธรรมอีสาน อักษรมอญ อักษรพม่า อักษรสิงหล อักษรโรมัน by มูลนิธิภูมิพโลภิกขุ เพื่อการค้นคว้าทางพระพุทธศาสนา, pp.57, 66.

- [Lanna] ระบบการเขียนอักษรลานนา by ผศ.ดร. อุดม รุ่งเรืองศรี, pp.72.

- [Lanna] ตำราเรียนอักขระลานนาไทย by สิงฆะ วรรณสัย, Chiang Mai University, pp.26.

- [Lanna] อักษรไทย by เรืองเดช ปันเขื่อนขัติย์, Mahidol University, pp.44, 58.

- [Lanna] ๑๓ เรียนภาษาล้านนาสัปดาห์ที่ ๖ ระห้าม ไม้กั๋งไหล tutorial video, start time: 09:14.
Never Shifted or Pseudo-Shifted. Mai Kang Lai is placed on the first consonant, probably shifted to the right, but logically, it is next to the first consonant. This can be distinguished from the shifted case by words with leading vowel next to Mai Kang Lai, such as สงฺโฆ and องฺเชิญ.
This is found in Khuen and some Lanna books.
- [Khuen] เขมรัฐนครเชียงตุง - Chieng Tung: Its Way of Life, pp. 235

- [Lanna] Wat Suan Dok book, pp. 42

- [Lanna] คู่มือการเรียนหนังสือตัวเมือง (แบบง่าย) by อ.สงบ เดชะวงศ์, pp. 6

- [Lanna] คู่มือเรียนภาษาไทยล้านนา ๒๔ ชั่วโมง ด้วยตนเอง by พระมหามิลินท์ อนาคาริโก, pp. 12
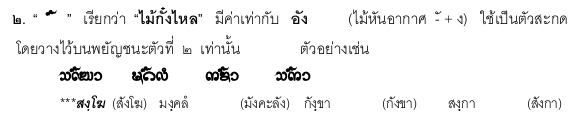
- [Lanna] อักษรธรรมล้านนา by เฉลียว มูลจันทร์, pp. 4,, 10

- [Lanna] แบบเรียนชุดพื้นฐาน เน้นกระบวนการเรียนรู้ ภาษาเมืองล้านนา by บุญคิด วัชรศาสตร์, pp. 23, 26, 186

Conditionally Shifted. Mai Kang Lai is shifted to the second consonant, except when some signs prevent it, such as MEDIAL RA or above vowel. Examples of such exceptions are รงฺสี, สงฺกรานต์.
This is found in some Lanna books, namely, Maefahluang dictionary of Northern Thai. Those Lanna books for behavior 1 do not provide examples to clarify these cases, though.
But a Lao Tham counter-example (by อ.ยุทธพงศ์ มาตย์วิเศษ above) confirms that Mai Kang Lai is still shifted even in these cases.