





tl;dr – buffer overflow But it’s a bit special kind of overflow. The copy fail exploits the overflow bug caused by mishandling in-place optimization in the algif_aead kernel module . The POC demonstrates that it can splice to read-only page cache, make it writable (because in-place ops must be read/write) . So, when load a … Continue reading Copy Fail
11 May 2026
Kitt

Copy Fail
12 April 2026
Kitt
วันสงกรานต์ พ.ศ.2569
วันสงกรานต์ปี 2569 เป็นปี จ.ศ. (2569 – 1181) = 1388 วันเถลิงศก ตรงกับ(1388 * 0.25875)+ floor(1388 / 100 + 0.38)– floor(1388 / 4 + 0.5)– floor(1388 / 400 + 0.595)– 5.53375= 359.145 + 14 − 347 − 4 − 5.53375= 16.61125= วันที่ 16 เมษายน 2569 เวลา 14:40:12 วันสงกรานต์ ตรงกับ16.61125 – 2.165 = 14.44625= วันที่ 14 เมษายน 2569 … Continue reading วันสงกรานต์ พ.ศ.2569
วันสงกรานต์ พ.ศ. 2568
วันสงกรานต์ปี 2568 เป็นปี จ.ศ. (2568 – 1181) = 1387 วันเถลิงศก ตรงกับ(1387 * 0.25875)+ floor(1387 / 100 + 0.38)– floor(1387 / 4 + 0.5)– floor(1387 / 400 + 0.595)– 5.53375= 358.88625 + 14 – 347 – 4 – 5.53375= 16.3525= วันที่ 16 เมษายน 2568 เวลา 08:27:36 วันสงกรานต์ ตรงกับ16.3525 – 2.165 = 14.1875= วันที่ 14 เมษายน 2568 … Continue reading วันสงกรานต์ พ.ศ. 2568
11 April 2026
Vee
Building an MCP Server with Common Lisp
I recently wanted to learn about MCP (Model Context Protocol). As someone whose default programming language is Common Lisp, I naturally decided to build an MCP server using Lisp.
Thanks to the creators of 40ants-mcp, the library provides a nice pattern and code structure that I really like. However, I struggled significantly with installation and getting started. What should have taken minutes ended up taking days.
I'm sharing my experience here so that others who want to build MCP servers in Common Lisp can get started in minutes, not days like I did.
Prerequisites
Before you begin, make sure you have the following installed:
- SBCL - A high-performance Common Lisp compiler
- Roswell - A Common Lisp implementation manager and script runner
- Quicklisp - The de facto package manager for Common Lisp
- Ultralisp - A community-driven distribution of Common Lisp libraries
Installing Ultralisp
In SBCL with Quicklisp, you can enable Ultralisp by:
(ql-dist:install-dist "http://dist.ultralisp.org/" :prompt nil)
(How to install SBCL and Quicklisp is in the appendix.)
The Gotcha: Loading 40ants-mcp
Here's the issue that cost me days: when you try to load 40ants-mcp with:
(ql:quickload :40ants-mcp)
You might encounter errors. The solution is simple but not obvious—load jsonrpc first:
(ql:quickload :jsonrpc)
(ql:quickload :40ants-mcp)
This dependency isn't automatically resolved, which was the source of my frustration.
Creating Your MCP Server
Here's a minimal example from my mcp-exper package:
(in-package :mcp-exper)
(openrpc-server:define-api (mi-tools :title "mi-tools"))
(40ants-mcp/tools:define-tool (mi-tools add) (a b)
(:summary "just add")
(:param a integer "a")
(:param b integer "b")
(:result text-content)
(make-instance 'text-content :text (format nil "~a" (+ a b))))
(defun start-server ()
(40ants-mcp/server/definition:start-server mi-tools))
Key points:
- Use
openrpc-server:define-apito define your API - Use
40ants-mcp/tools:define-toolto define tools - Return
text-contentinstances for text results (MCP requires specific content types)
Running the Server
Create a Roswell script (mi-mcp-server.ros):
#!/bin/sh
#|-*- mode:lisp -*-|#
exec ros -Q -- $0 "$@"
|#
(progn
(ros:ensure-asdf)
#+quicklisp(ql:quickload '(:mcp-exper) :silent t))
(defun main (&rest argv)
(declare (ignorable argv))
(mcp-exper:start-server))
Quick Test
Run directly with Roswell:
ros mi-mcp-server.ros
Production Installation
Build and install as an executable:
ros build mi-mcp-server.ros
install -m 0755 mi-mcp-server $HOME/.local/bin/
Make sure $HOME/.local/bin is in your PATH.
Integrating with Opencode
To enable your MCP server in opencode, add this to ~/.config/opencode/opencode.json:
{
"mcp": {
"mi-tools": {
"type": "local",
"command": ["mi-mcp-server"],
"enabled": true
}
}
}
Conclusion
Building MCP servers with Common Lisp is straightforward once you know the tricks. The 40ants-mcp library is well-designed, and the OpenRPC integration works smoothly.
I hope this guide saves you the days of frustration I experienced. Happy hacking!
The full source code for this example is available at mcp-exper.
Appendix: Installing SBCL
macOS
brew install sbcl
Debian/Ubuntu
apt install sbcl
Arch Linux
pacman -S sbcl
Appendix: Installing Quicklisp
Download and install Quicklisp:
wget https://beta.quicklisp.org/quicklisp.lisp
sbcl --load quicklisp.lisp \
--eval '(quicklisp-quickstart:install)' \
--eval '(ql-util:without-prompting (ql:add-to-init-file))' \
--quit
19 January 2026
Vee
Validating Native Python: A Practical Approach with baredtype
In Python development, we often default to using basic data structures like dict and list to move data around. They are flexible, JSON-compatible, and require no special setup. With the recent advancements in TypedDict and Annotated, the Python type system has become powerful enough to describe these structures with high precision.
baredtype is a library built to bridge the gap between these native structures and formal validation. It allows you to enforce strict rules on your data without ever forcing that data to change its shape or type.
The Strength of Basic Data Structures
The main draw of baredtype is that it works directly with the data structures you already use. There is no custom class instantiation or "wrapping" of data into library-specific objects.
Serialization and Deserialization
Because your data remains a standard list or dict, you don't need special methods to get your data in or out of a system. You use the standard tools you already know:
-
To JSON:
json.dumps(my_data) -
From JSON:
json.loads(input_string) -
Validation:
validate(MySchema, my_data)
Handling Keys and None Values
Working with native structures means using standard Python idioms. baredtype respects TypedDict definitions for required fields and Annotated for value constraints, allowing you to handle None values and missing keys naturally.
from typing_extensions import TypedDict, NotRequired, Annotated
from baredtype import validate
class UserData(TypedDict):
username: str
email: Annotated[str | None, {"pattern": r"^[\w.-]+@[\w.-]+\.\w+$"}]
age: NotRequired[int]
# Use standard Python to check your data:
data = {"username": "tech_lead", "email": None}
if data.get("email") is None:
print("No email provided.")
if "age" not in data:
print("Age is an optional key.")
# Validation checks the types and the constraints
is_valid = validate(UserData, data)
Mapping to JSON Schema and OpenAPI
A core objective of baredtype is making it easy to map Python types to external standards like JSON Schema and OpenAPI. It handles the "quantifiers" that define how different types can be combined.
Quantifier Logic
-
oneOf: By usingAnnotatedmetadata, you can specify that data must match exactly one type in a Union. This is crucial for precise API definitions where ambiguity can lead to bugs. -
allOf: This is naturally supported throughTypedDictinheritance. When oneTypedDictinherits from others,baredtypegenerates a schema representing the union of those requirements, staying consistent with OpenAPI standards.
Two Ways to Verify the Spec
When we define our data structures, we are writing a specification for our code. There are two primary ways to ensure our code follows this spec, both of which are supported by baredtype.
1. Static Type Checking
Because the library is built on TypedDict, you get the full benefit of tools like Mypy or Pyright. Your IDE can catch missing keys or type mismatches while you are writing the code. This finds errors before the code ever runs.
2. Property-Based Checking
While static types prove what should happen, property-based checking proves what can happen under stress. baredtype integrates with Hypothesis to automatically generate data that fits your TypedDict definitions, including constraints like min_length or regex patterns.
from baredtype import given_from_annotations
@given_from_annotations
def test_process_payload(payload: UserData):
# Hypothesis generates a wide variety of valid UserData dicts
# to find edge cases in your logic.
result = my_function(payload)
assert result is not None
Validation: The Constant Requirement
Regardless of whether you use static checking, property-based checking, or both, runtime validation is a must. External data is inherently untrusted. Static checking verifies your internal logic, and property-based testing verifies your code's resilience during development. At the moment data enters your system, baredtype provides the final, essential check to ensure the data actually matches your specification.
Explore the Project
baredtype offers a lightweight validation layer that stays out of your data's way, leveraging the emerging strengths of the Python type system.
Check out the project on Codeberg:
👉 https://codeberg.org/veer66/baredtype
8 January 2026
Thep

Addressing fonts-arundina Unreproducibility
มีเวลากลับมาทำงานของ Debian รอบนี้ เรื่องหนึ่งที่ทิ้งคาราคาซังไว้นานคือ ปัญหา unreproducible ของ fonts-arundina ที่สาเหตุหลักเกิดจาก timestamp ที่ Fontforge สร้าง
ความจริงปัญหานี้ควรหมดไปนานแล้ว ตั้งแต่มีข้อกำหนด SOURCE_DATE_EPOCH เพื่อให้ซอฟต์แวร์ต่างๆ ใช้ timestamp จาก changelog ล่าสุดของ distro แทนการใช้เวลาขณะ build ที่เปลี่ยนไปเรื่อยในการ build แต่ละครั้ง และ FontForge ก็ได้รับแพตช์ที่ Debian เสนอไปตั้งนานแล้วใน fontforge#2490
ก่อนหน้านี้ผมเคยตรวจสอบมารอบหนึ่งแล้ว ก็ยังไม่เจอสาเหตุของปัญหา จึงสรุปว่าจะ workaround ไปก่อนด้วยการตัด timestamp ออกเสียเลยใน 2 commit (ใช้ sed ตัดข้อมูลใน AFM และ PFB โดยตรง, ปรับวิธีการตัดข้อมูลใน PFB ซึ่งเป็น binary) โดยนอกจาก timestamp แล้ว ก็ตัดข้อมูล Creator ที่ดันไปเอาข้อมูล user ของ build process มาแปะออกด้วย เพราะมันทำให้ขึ้นอยู่กับคนที่สั่ง build deb ซึ่งจะเป็นใครก็ได้
แต่ก็ยังเหลือปัญหาข้อมูล ItalicAngle ที่อาจใช้ comma แทนจุดทศนิยมอยู่ ซึ่งเป็นพฤติกรรมที่ขึ้นกับ locale ของระบบที่ build
แต่หลังจากที่ตัดข้อมูล creation ออกไปแล้ว ก็อยากแกะรอยหาปัญหาที่แท้จริงของ FontForge อีกสักตั้ง นั่งไล่โค้ดก็เห็นใช้ค่าจาก SOURCE_DATE_EPOCH ในฟังก์ชัน GetTime() ที่ใช้อยู่ทั่วทั้งแอปอยู่แล้ว ถ้าเช่นนั้น timestamp มันยัง vary อยู่ได้ยังไง?
รอบนี้ได้คำตอบจนได้ คือ timestamp มันเป็นสตริงที่สร้างด้วยฟังก์ชัน ctime() ของ Standard C Library ซึ่งมีการพิจารณา timezone ที่ initialize ไว้โดยฟังก์ชัน tzset() ด้วย โดยถ้าตัวแปร environment TZ มีการกำหนดค่า ก็จะมีการชดเชยนาฬิกากลับเป็น GMT ตาม timezone ที่กำหนด ซึ่งถ้าระบบที่ build เกิดมีการกำหนด TZ ขึ้นมา มันก็จะปรับค่า epoch ใน $SOURCE_DATE_EPOCH จาก timezone ใน $TZ ให้เป็น GMT แต่ปัญหาคือ epoch ใน $SOURCE_DATE_EPOCH มันเป็น GMT อยู่แล้วตั้งแต่ต้น ไปปรับซ้ำอีกมันก็เลยเพี้ยน!
กล่าวคือ โปรแกรม reprotest ได้กำหนดการกลั่นแกล้งไว้ด้วยตัวแปร environment TZ ใครไม่ระวังเรื่องนี้ก็ fail นั่นเอง
สรุปรวบยอดว่าปัญหา unreproducible ของ fonts-arundina และวิธีแก้คือ:
- timestamp ของ Creation Date เพี้ยน: แก้โดยกำหนด environment
TZ=GMT - ข้อมูล Creator ที่ไปอ่านข้อมูลจาก user ID ของโพรเซสที่ build มาแปะ: แก้โดย override environment
USER="<ชื่อผู้แก้ไขฟอนต์ล่าสุด>" - ค่า
ItalicAngleมีรูปแบบทศนิยมที่ขึ้นอยู่กับ locale: แก้โดยกำหนด locale ด้วยLC_ALL=C
ด้วยวิธีแก้ข้างต้น เราจะสามารถ revert การตัดข้อมูลการ create ฟอนต์ออก แล้วคงข้อมูลดังกล่าวแบบ reproducible ได้ แลกกับความรกรุงรังของคำสั่ง build นิดหน่อย
แต่จะคงข้อมูลการ create ไว้หรือไม่? ก็ต้องตอบคำถามว่า ข้อมูล creation date, creator มีประโยชน์อะไรไหม? มันอาจช่วยแยกแยะ version ของฟอนต์ได้? ถ้ายังมีประโยชน์ก็อาจเอากลับมา ไม่งั้นก็ตัดทิ้ง
คิดสะระตะแล้ว ข้อมูล creation date, creator อาจเคยมีประโยชน์เมื่อนักพัฒนาฟอนต์เก็บไฟล์ source ไว้กับตัว จะปล่อยฟอนต์เมื่อไรก็ generate ทำให้ข้อมูลการ create บ่งบอกการ release แต่พอเป็น open source ที่ทุกคนสามารถมี source อยู่ในมือ ผู้พัฒนากับผู้ generate ก็อาจเป็นคนละคนกัน การพยายามบอกว่าใครเป็นผู้ generate จึงไม่มีความหมายเท่าไร ในเมื่อ generate แต่ละครั้งก็มาจาก source เดิม เนื้อหาก็คงเดิม
ข้อมูลที่ควรจำแนกเนื้อหาฟอนต์ได้ดีกว่าคือฟิลด์ Version ในฟอนต์ ที่ผู้พัฒนาควรปรับค่าทุกครั้งที่ปล่อยอยู่แล้ว
สรุป: ไม่เอาข้อมูลการ create กลับมา ตัดแล้วตัดเลย ทำเพิ่มคือการบังคับ C locale เพื่อควบคุมรูปแบบจุดทศนิยม
27 December 2025
Vee
Revisiting codebase organization practices from 2004
I reviewed the file and directory structure of several web-based free software projects released in 2003–2004: the Koha 1.2.0 library management system, the MRBS 1.2.1 meeting room booking system, and the DSpace 1.2 content repository system. These were written in Perl, PHP, and Java, respectively.
Endpoint files are named using an action, optionally followed by an entity, following patterns such as search.pl, search.php, SimpleSearchServlet.java, updatebibitem.pl, edit_entry.php, and EditProfileServlet.java. These verbs or verb phrases may or may not align with user workflows. For example, Koha includes opac_reserve.pl, indicating it handles the reservation workflow via the Online Public Access Catalog (OPAC) API. However, there is no dedicated "borrow" endpoint file.
Each system is designed in a modular style. Koha has a Borrower.pm module that provides a reserveslist function; MRBS uses functions.inc with functions such as make_room_select_html; and DSpace's Item.java includes methods like findAll. That said, they do not strictly follow a multi-tier architecture, for instance, database queries are not isolated into a dedicated data access layer. Still, DSpace, by using Servlets and JSPs, does establish a distinct presentation layer.
Because of the verb-based naming convention, files emphasize what they do rather than which architectural layer they belong to. This makes their purpose easy to understand at a glance.
However, this approach can make organization and testing more challenging. Logic, database queries, and presentation code are often mixed; sometimes not even separated into distinct functions.
13 December 2025
Vee
Global Variables in Python Are Not That Global
In the context of programming in the 1980s, "global variables" likely brings to mind languages like MBASIC. However, using MBASIC as an example today would be challenging, as it is now rarely used or known. Instead, GNU Bash, which is the default shell scripting language for many systems—will be used to illustrate what global variables were traditionally like. Anyway, some might think of Fortran II, but I'm not familiar with it.
Bash Example
I wrote a Bash script consisting of four files:
a.bash
a.bash orchestrates everything. "Orchestration" might be too grand a word for these toy scripts, but I want to convey that it performs a role similar to Apache Airflow.
#!/bin/bash
. ./b.bash
. ./c.bash
. ./d.bash
init
print_count
inc
print_count
b.bash
b.bash contains only one function, inc, which increments the counter, which is the global variable in this example.
inc() {
counter=$((counter + 1))
}
c.bash
c.bash contains print_count, which simply displays the value of the global variable counter.
print_count() {
echo $counter
}
d.bash
In Bash, counter can be initialized globally from within a function by default.
init() {
counter=1
}
Python Example
The following section shows the result of porting the Bash script above to Python, highlighting the key differences.
a.py
This is the orchestration part. Note the use of namespaces or module names.
import c, b, d
d.init()
c.print_count()
b.inc()
c.print_count()
b.py
In the Python version, inc must refer to the module d to access the variable. Alternatively, counter could be explicitly imported.
import d
def inc():
d.counter += 1
c.py
Similarly, print_count in Python must also refer to module d.
import d
def print_count():
print(d.counter)
d.py
Unlike in Bash, initializing a global variable from within a function—even in the same module—requires an explicit global declaration.
def init():
global counter
counter = 1
Key Differences
As you can see, a global variable in Bash is truly global across files. In Python, however, a global variable is only global within its module, i.e., file. Furthermore, mutating a global variable in Bash requires no special syntax, whereas in Python a function must explicitly declare global to modify a module-level variable.
Consequently, although both are called "global variables," Python's are scoped to the module. This means they won’t interfere with variables in other modules unless we deliberately make them do so. For developers who use one class per module, a Python global variable behaves much like a class variable. Additionally, variable assignment inside a Python function is local by default, preventing accidental modification of global state unless explicitly intended.
In short, many traditional precautions about global variables in languages like Bash or MBASIC no longer apply in Python. Therefore, we might reconsider automatically rejecting global variables based on past advice and instead evaluate their use case thoughtfully.
23 November 2025
Vee
A lesson about abstraction from Arch Linux
I was impressed by pkgsrc because it is a powerful package management system that defines packages using a common tool like a Makefile. I later discovered that the PKGBUILD file is even more impressive, as its purpose is immediately clear. I initially attributed this to my greater familiarity with Bash scripting compared to Makefiles, but I now believe the true reason is PKGBUILD's level of abstraction.
It retains explicit calls to configure and make, preserving the transparency of a manual installation. This demonstrates that while increased abstraction can make code shorter, it can also hinder understanding.
Another potential advantage of greater abstraction is the ability to change the configure command for every package by modifying just one location. However, since GNU Autotools has continued to use the configure command for decades, it may not be worth sacrificing clarity for this particular benefit.
1 November 2025
Kitt
หยี่แปะ
อากง อาม่า ของ อจก. เป็นจีนแต้จิ๋ว อพยพหนีความแร้นแค้นมาจากซัวเถา เมื่อเกือบจะร้อยปีก่อน มีลูก 5 คน พอมาอยู่ไทยเลยใช้นามสกุล แซ่เตีย (张) ตามอากง จนลุงคนรอง (หยี่แปะ) ไปขอจดใช้นามสกุล ธโนปจัย ภายหลังพบว่าไปซ้ำกับนามสกุลที่มีมาก่อนแล้ว เลยเปลี่ยนเป็น “เธียรธโนปจัย” ลุงน่าจะเป็นคนเดียวในครอบครัวเราที่เคยใช้นามสกุล ธโนปจัย ปรากฏ ชื่อ-สกุล ในวิทยานิพนธ์ ป.โท ของจุฬาฯ ปี 2517 ก่อนจะเปลี่ยนมาใช้ เธียรธโนปจัย ด้วยกันหลังจากนั้น ลุงทำงานธนาคาร ไปสุดตำแหน่งใหญ่ใน HQ แถวสีลม ไม่มีครอบครัว สันโดษ early มา day trade ดูแลอาม่าช่วงก่อนอาม่าเสีย กับเลี้ยงหมา ๆ ที่บ้าน พอหมา ๆ ตายไปหมด ก็เริ่มมีอาการ Alzheimer หนักขึ้น มาช่วง COVID-19 … Continue reading หยี่แปะ
30 October 2025
Kitt
Microsoft BitLocker ..
BitLocker มัน on เองจริง ๆ ด้วย … (- -)a .. ไม่ได้ logon Microsoft Account ก็โดน
About TH Sarabun
เรื่องสมมติที่เกิดขึ้นจริง สิบสองปีก่อนโน้น Google Docs ยังใช้ภาษาไทยไม่ได้ดีเท่าทุกวันนี้ อจก. กับ FOSS dev หยิบมือนึง อยากเอาฟอนต์ TH Sarabun New เข้าไปอยู่ใน Google Docs จะได้สร้างเอกสารภาษาไทยได้สมบูรณ์ขึ้น โดยเฉพาะเอกสารราชการซึ่งมีมติฯ ให้ใช้ TH Sarabun PSK (อ่านต่อไปเรื่อย ๆ จะเข้าใจ PSK กับ New) และบังเอิญหยิบมือนั้นได้คุยกับ Dave Crossland คนที่ทำโครงการ Google Fonts .. เวลานั้น Dave บอก อจก. ว่ากำลังจะมาเมืองไทยพอดี ถ้าจะให้ workshop เรื่องฟอนต์ สัญญาอนุญาต การออกแบบ โปรแกรม Dave ยินดีมาก ๆ สำหรับหยิบมือนั้น การคุยกันกับ Dave เป็นการปักหมุด เรื่องฟอนต์ไทยไป … Continue reading About TH Sarabun
2 September 2025
Vee
Reasons to use Emacs in 2025
Expanding Emacs functionality is as simple as defining a new function instead of creating an entire extension package, as is often done in many other extensible editors. This function can then be re-evaluated, tested, and modified entirely within Emacs using just a few clicks or keyboard shortcuts, with no need to restart or reload Emacs.
17 August 2025
Vee
Reasons to use Common Lisp in 2025
Reasons to use Common Lisp
An actively-maintained-implementation, long-term-stable-specification programming language
There are many programming languages that don't change much, including
Common Lisp, but Common Lisp implementations continue to be developed.
For example, SBCL (Steel Bank Common Lisp) released its latest version
just last month.
Common Lisp can be extended through libraries. For example, cl-interpol
enables Perl-style strings to Common Lisp without requiring a new
version of Common Lisp. cl-arrows allows Common Lisp to create pipelines
using Clojure-style syntax without needing to update the Common Lisp
specification. This exceptional extensibility stems from macro and
particularly reader macro support in Common Lisp.
Feature-packed
Common Lisp includes many features found in modern programming
languages, such as:
- Garbage collection
- Built-in data structures (e.g., vectors, hash tables)
- Type hints
- Class definitions
- A syntactic structure similar to list comprehensions
Multi-paradigm
While Lisp is commonly associated with functional programming, Common
Lisp doesn't enforce this paradigm. It fully supports imperative
programming (like Pascal), and its object-oriented programming system
even includes advanced features. Best of all, you can freely mix all
these styles. Common Lisp even embraces goto-like code via TAGBODY-GO.
Performance
Common Lisp has many implementations, and some of them, such as SBCL,
are compilers that can generate efficient code.
With some (of course, not all) implementations, many programs written in
dynamic programming languages run slower than those in static ones, such
as C and Modula-2.
First, an example of the generated assembly will be shown, along with
more explanation about why it might be slowed down by some dynamic
implementations
The code listing below is a part of a program written in Modula-2, which
must be easy to read by programmers of languages in the extended ALGOL
family.
TYPE
Book = RECORD
title: ARRAY[1..64] OF CHAR;
price: REAL;
END;
PROCEDURE SumPrice(a, b: Book): REAL;
BEGIN
RETURN a.price + b.price;
END SumPrice;
The code is mainly for summing the price of books, and only the part
'a.price + b.price' will be focused on.
'a.price + b.price' is translated into X86-64 assembly code list below
using the GNU Modula-2 compiler.
movsd 80(%rbp), %xmm1
movsd 152(%rbp), %xmm0
addsd %xmm1, %xmm0
"movsd 80(%rbp), %xmm1' and 'movsd 152(%rbp), %xmm0' are for loading
'prices' to registers '%xmm1' and '%xmm0', respectively. Finally, 'addsd
%xmm1, %xmm0' is for adding prices together. As can be seen, the prices
are loaded from exact locations relative to the value of the '%rbp'
register, which is one of the most efficient ways to load data from
memory. The instruction 'addsd' is used because prices in this program
are REAL (floating point numbers), and '%xmm0', '%xmm1', and 'movsd' are
used for the same reason. This generated code should be reasonably
efficient. However, the compiler needs to know the type and location of
the prices beforehand to choose the proper instructions and registers to
use.
In dynamic languages, 'SumPrice' can be applied to a price whose type is
an INTEGER instead of a REAL, or it can even be a string/text. A
straightforward implementation would check the type of 'a' and 'b' at
runtime, which makes the program much less efficient. The checking and
especially branching can cost more time than adding the numbers
themselves. Moreover, obtaining the value of the price attribute from
'a' and 'b' might be done by accessing a hash table instead of directly
loading the value from memory. Of course, while a hash-table has many
advantages, it's less efficient because it requires many steps,
including comparing the attribute name and generating a hash value.
However, compilers for dynamic languages can be much more advanced than
what's mentioned above, and SBCL is one such advanced compiler. SBCL can
infer types from the code, especially from literals. Moreover, with
information from type hints and 'struct' usage, SBCL can generate code
that's comparably as efficient as static language compilers.
Given, the Common Lisp code listing below:
(defstruct book
title
(price 0 :type double-float))
(declaim (ftype (function (book book) double-float) add-price)
(optimize (speed 3) (debug 0) (safety 0)))
(defun add-price (a b)
(+ (book-price a)
(book-price b)))
SBCL can generate assembly code for '(+ (book-price a) (book-price b))'
as shown below:
; 86: F20F104A0D MOVSD XMM1, [RDX+13]
; 8B: F20F10570D MOVSD XMM2, [RDI+13]
; 90: F20F58D1 ADDSD XMM2, XMM1
The assembly code format is slightly different from the one generated by
the GNU Modula-2 compiler, but the main parts, the 'MOVSD' and 'ADDSD'
instructions and the use of XMM registers—are exactly the same. This
shows that we can write efficient code in Common Lisp at least for this
case. This shows that we can write efficient code in Common Lisp, at
least in this case, that is as efficient as, or nearly as efficient as,
a static language.
This implies that Common Lisp is good both for high-level rapid
development and optimized code, which has two advantages: (1) in many
cases, there is no need to switch between two languages, i.e., a
high-level one and a fast one; (2) the code can be started from
high-level and optimized in the same code after a profiler finds
critical parts. This paradigm can prevent premature optimization.
Interactive programming
Interactive programming may not sound familiar. However, it is a common
technique that has been used for decades. For example, a database engine
such as PostgreSQL doesn't need to be stopped and restarted just to run
a new SQL statement. Similarly, it is akin to a spreadsheet like Lotus
1-2-3 or Microsoft Excel, which can run a new formula without needing to
reload existing sheets or restart the program.
Common Lisp is exceptionally well-suited for interactive programming
because of (1) integrated editors with a REPL (Read Eval Print Loop),
(2) the language's syntax, and (3) the active community that has
developed libraries specifically designed to support interactive
programming.
Integrated editors with a REPL
With an integrated with a REPL, any part of the code can be evaluated
immediately without copying and pasting from an editor into a REPL. This
workflow provides feedback even faster than hot reloading because the
code can be evaluated and its results seen instantaneously, even before
it is saved. There are many supported editors, such as Visual Studio
Code, Emacs, Neovim, and others.
the language's syntax
Instead of marking region arbitrarily for evaluating, which is not very
convenient when it is done every few seconds, in Common Lisp, we can
mark a form (which is similar to a block in ALGOL) by moving a cursor to
one of the parentheses in the code, which is very easy with structural
editing, which will be discussed in the next section.
Moreover, even a method definition can be evaluated immediately without
resetting the state of the object in Common Lisp. Since method
definitions are not nested in defclass, this allows mixing interactive
programming and object-oriented programming (OOP) smoothly.
Here's the corrected code listing:
(defclass toto ()
((i :initarg :i :accesor i)))
(defmethod update-i ((obj toto))
(setf (i obj) (+ i obj) 1))
According to the code listing above, the method 'update-i' can be
redefined without interfering with the pre-existing value of 'i'.
Structural editing
Instead of editing Lisp code like normal text, tree-based operations can
be used instead, such as paredit-join-sexps and
paredit-forward-slurp-sexp. Moving cursor operations, such as
paredit-forward, which moves the cursor to the end of the form (a
block). These structural moving operations are also useful for selecting
regions to be evaluated in a REPL.
Conclusion
In brief, Common Lisp has unparalleled combined advantages, which are
relevant to software development especially now, not just an archaic
technology that just came earlier. For example, Forth has a
long-term-stable specification, and works well with interactive
programming, but it is not designed for defining classes and adding type
hints. Julia has similar performance optimization and OOP is even
richer, but it doesn't have a long-term-stable specification. Moreover,
Common Lisp's community is still active, as libraries, apps, and even
implementations continue to receive updates.
25 July 2025
Thep
Tai Tham Updated, Thai Noi Revisited
Update งานอักษรอีสาน
Khottabun กับอักษรธรรมแบบไร้ USE
หลังจากการวิเคราะห์ทางเลือกต่างๆ สำหรับอักษรธรรมไป 2 blog (Lao Tham Font vs USE และ To USE or Not to USE for Lao Tham) และได้ตัดสินใจ หลีกเลี่ยง USE โดยยอมทิ้ง MS Word ไว้ข้างหลัง ก็ได้ implement ใน fonts-khottabun ตามนั้น ตั้งแต่ commit a0389bd จนถึง commit 1c73c80 โดยปรับ major version ของฟอนต์ขึ้นเป็นรุ่น 003 สำหรับอักษรธรรมแบบไม่ใช้ USE
Keyboard Layout อักษรธรรมบน Windows
ถัดมาคือ ผังแป้นพิมพ์อักษรธรรมบน Windows ในรูปของซอร์ส KLC สำหรับสร้างเป็นผังแป้นพิมพ์ด้วย Microsoft Keyboard Layout Creator (MSKLC) 1.4 ซึ่งจะ build เป็น DLL พร้อมโปรแกรม setup
ประเด็นปลีกย่อยของผังนี้คือ Windows กำหนดให้ผังแป้นพิมพ์ต้องผูกติดกับโลแคล (locale) ซึ่งกำหนดด้วยภาษาและดินแดน ตรงนี้เป็นปัญหาโดยนิยามอยู่ เพราะอักษรธรรมสามารถใช้เขียนได้หลายภาษา ไม่ว่าจะไทย ลาว ไทลื้อ ไทขึน หรือคาถาบาลี-สันสกฤต แต่ Windows จะบังคับให้เราเลือกเพียงภาษาเดียวมาประกอบกับดินแดนที่เป็นถิ่นของภาษาที่ใช้ โดยห้ามใช้ซ้ำกับผังอื่นในโลแคลนั้นๆ ด้วย ประเด็นคือ:
- โลแคลต่างๆ มักมีผังแป้นพิมพ์อยู่แล้ว ถ้าไม่ต้องการซ้ำก็ต้องสร้างโลแคลใหม่สำหรับอักษรธรรม แต่จะกำหนดโลแคลด้วยภาษาอะไร ในเมื่ออักษรธรรมสามารถใช้เขียนได้หลายภาษา?
- สมมุติว่าเราเลือกสร้างโลแคลภาษาลาวถิ่นไทย (
lo-TH) ด้วย Microsoft Locale Builder แต่ปัญหาคือ เราไม่สามารถเลือกบล็อคยูนิโคดของอักษรธรรมให้กับโลแคลใหม่นี้ได้ เนื่องจาก Microsoft กำหนดตัวเลข enum ให้กับบล็อคยูนิโคดต่างๆ แต่ยังไม่ได้กำหนดเลขสำหรับอ้างให้กับบล็อคอักษรธรรม! - ในเมื่อสร้างโลแคลเองไม่ได้ วิธีแก้ขัดจึงเป็นการเลือกโลแคลอะไรก็ได้ที่ไม่ซ้ำกับชุดผังแป้นพิมพ์ที่เราใช้ เช่น ใช้ th, en ไม่ได้ เพราะจะซ้ำกับสองผังหลักที่เราใช้ และผมก็จิ้มเอาโลแคลมลยาฬัมในอินเดีย (
ml-IN) โดยไม่มีเหตุผลใดๆ มากไปกว่าการแก้ขัด เวลาจะป้อนอักษรธรรมบน Windows ผู้ใช้ก็สลับแป้นพิมพ์ไปที่ภาษามลยาฬัม - อันที่จริง สิ่งที่เราต้องการมากกว่าในกรณีนี้คือการอ้างถึง
อักษร
(script) ตรงๆ ไปเลย แต่การออกแบบของ Windows ยังไม่เอื้อขนาดนั้น
อย่างไรก็ดี เราก็ได้ผังแป้นพิมพ์อักษรธรรมที่ทำงานได้บน Windows โดยเป็นเพียงผังปุ่มจริงๆ ยังไม่มีการตรวจหรือสลับลำดับอะไร ผู้ใช้ต้องป้อนตามลำดับยูนิโคดเป๊ะๆ เช่น ᨸᩮᩢ᩠ᨶ (เป็น) ก็ต้องป้อนเป็น ป + เอ + ไม้ซัด + SAKOT + น
อักษรไทยน้อย
แม้อักษรไทยน้อยจะเรียบง่ายกว่าอักษรธรรม แต่กลับมีรายละเอียดปลีกย่อยมากกว่า ทั้งเรื่องความหลากหลายของชุดอักษรที่ใช้ การควบอักษรติดกัน การยืมตัวห้อยตัวเฟื้องจากอักษรธรรมตามแต่ผู้จารึกจะเลือกใช้ ดังที่ผมได้เคย สรุปประเด็น ไว้ โดยยังไม่ตกลงว่าจะเลือก implement แบบไหน
เมื่อหลายปีก่อน ในระหว่างที่ทำไปศึกษาไปนั้น ผมเลือกที่จะเติมอักขระลงในช่องที่ยังว่างอยู่ของบล็อคยูนิโคดอักษรลาว ไม่ว่าจะเป็นตัวเฟื้องหรือตัวควบต่างๆ แต่ยิ่งพบอักขระที่ต้องเพิ่มรหัสมากขึ้นจากการอ่านจารึก ก็ยิ่งเห็นว่ามันไม่ใช่วิธีที่ดีในระยะยาว
ตอนนี้ได้โอกาสมาปัดฝุ่น โดยบล็อคยูนิโคดลาวเองก็มีมีการเพิ่มอักขระสำหรับเขียนภาษาบาลีตามแบบพุทธบัณฑิตสภา จึงได้พิจารณาทางเลือกต่างๆ ใหม่
เริ่มจากตรวจสอบความคืบหน้าใน Unicode ของอักษรไทยน้อย ซึ่ง ข้อมูลใน ScriptSource ของ SIL ได้บันทึกรายละเอียดไว้ โดยสถานะล่าสุดคือ ยังไม่กำหนดใน Unicode ส่วนกระบวนการเท่าที่ผ่านมาคือ
- 2018-01-02 Request to Add Thai Characters — Nitaya Kanchanawan (WG2 N4927, L2/18-041)
- เป็นข้อเสนอขอเพิ่มอักขระไทยน้อยลงในบล็อคอักษรไทย! โดยเป็นงานที่เกี่ยวเนื่องกับการกำหนดมาตรฐานการถอดอักษรไทยน้อยเป็นอักษรโรมันที่ราชบัณฑิตยสภาได้เสนอเข้าสู่ ISO/IEC โดยได้รับความเห็นว่าควรกำหนดรหัสอักขระก่อน แต่ไม่ทราบว่าด้วยเหตุผลใด ราชบัณฑิตยสภาถึงได้เสนอให้เพิ่มอักขระในบล็อคอักษรไทยแทนที่จะเป็นบล็อคอักษรลาวที่อยู่ในสายวิวัฒนาการโดยตรง
- 2018-01-19 Information and documentation - Transliteration of scripts in use in Thailand - Part 1: Transliteration of Akson-Thai-Noi — TC46 / WG3 (WG2 N4927A, L2/18-042)
- เป็นร่างมาตรฐานการถอดอักษรไทยน้อยเป็นอักษรโรมันที่เป็นต้นเรื่อง ตัวเอกสารต้องใช้รหัสผ่านในการเข้าถึง และไม่เกี่ยวข้องกับเรื่องรหัสอักขระโดยตรง ผมจึงไม่ใส่ลิงก์ไว้
- 2018-01-19 Results on ISO CD 20674-1: Information and documentation - Transliteration of scripts in use in Thailand - Part 1: Transliteration of Akson-Thai-Noi — TC46 Secretatriat (WG2 N4927B, L2/18-043)
- ผลการโหวตร่างมาตรฐานการถอดอักษรไทยน้อยของคณะกรรมการ เห็นชอบ 16, เห็นชอบโดยมีข้อคิดเห็น 2, ไม่เห็นชอบ 1, งดออกเสียง 19
- 2018-02-20 Thai-Noi Transliteration — Martin Hosken (WG2 N4939, L2/18-068)
- เป็นความเห็นจากคุณ Martin Hosken ผู้เชี่ยวชาญจาก SIL โดยสรุปเห็นว่าอักษรไทยน้อยเข้ากันได้กับอักษรธรรมมากกว่าอักษรไทย
- 2018-02-28 Towards a comprehensive proposal for Thai Noi / Lao Buhan script — Ben Mitchell (L2/18-072)
- เป็นความเห็นจากคุณ Ben Mitchell ผู้เชี่ยวชาญอีกท่านหนึ่ง โดยมีผู้ร่วมให้ข้อมูลคือ Patrick Chew, ผมเอง และ อ.ประพันธ์ เอี่ยมวิริยะกุล โดยสรุปเห็นว่าควรเพิ่มอักขระไทยน้อยในบล็อคอักษรลาว โดยเพิ่มเติมจากอักษรลาวบาลีของพุทธบัณฑิตสภาอีกที และได้เสนอทางเลือกต่างๆ ดังที่ผมได้สรุปไว้ แต่ยังไม่ระบุว่าจะเลือกวิธีการไหน
- Recommendations to UTC #155 April-May 2018 on Script Proposals (L2/18-168) (อยู่ที่ข้อ 6.) และบันทึกการประชุมของ UTC #155 (L2/18-115) (อยู่ที่ข้อ D.8.1 และ D.8.3)
- สรุปข้อแนะนำของคณะกรรมการว่าอักษรไทยน้อยไม่ใข่ส่วนขยายของอักษรไทย และผู้เสนอร่างอักษรไทยน้อย (หมายถึง อ.นิตยา กาญจนวรรณ จากราชบัณฑิตยสภา) ควรนำข้อมูลในเอกสารของคุณ Ben Mitchell ข้างต้นไปใช้ประกอบการร่างด้วย โดยมอบให้ Deborah Anderson ร่างเอกสารแจ้งเจ้าของร่าง ซึ่งก็คือเอกสาร L2/18-070
แล้วกระบวนการทั้งหมดก็หยุดอยู่ที่รอการดำเนินการของราชบัณฑิตยสภาต่อจากนั้น
สรุปว่ายังไม่มีมาตรฐาน Unicode อักษรไทยน้อยเกิดขึ้น ถ้าจะ implement ตอนนี้ก็เป็นเพียงตุ๊กตาเท่านั้น
จากทางเลือกต่างๆ ที่มี ผมพิจารณาเลือกเองไปก่อนอย่างนี้:
- Conjunct หรือการสังโยคพยัญชนะด้วยตัวห้อย/ตัวเฟื้อง ใช้พินทุ (U+0EBA LAO SIGN PALI VIRAMA) ตามด้วยพยัญชนะที่จะสังโยค ยกเว้นกรณีที่มีรหัสอยู่แล้ว คือ ล ห้อย (U+0EBC) และ ย เฟื้อง (U+0EBD) ก็ใช้รหัสนั้นๆ ไปเลย
- Ligature หรือตัวแฝด หรืออักษรควบ ใช้ U+200D ZERO WIDTH JOINER (ZWJ) เชื่อมพยัญชนะ ยกเว้นกรณีที่มีรหัสอยู่แล้ว คือ U+0EDC (ໜ), U+0EDD (ໝ) ก็ใช้รหัสนั้นๆ ไปเลย
- สระออย กำหนดอักขระใหม่ในช่องที่ยังว่างอยู่ คือ U+0EBE เพื่อให้เป็นวิธีที่สอดคล้องกับอักษรธรรม (อีกวิธีที่ไม่ต้องกำหนดอักขระใหม่คือใช้ พินทุ + ຢ แต่จะเป็นวิธีที่แปลกแยกจากอักษรธรรม)
เมื่อเลือกวิธีนี้แล้ว ก็ปรับเปลี่ยนทั้งในฟอนต์ Khottabun และในระบบป้อนข้อความ Lanxang ดังนี้:
-
fonts-khottabun: detach glyph ตัวห้อย/ตัวเฟื้องและตัวควบทั้งหมดจากรหัสอักขระ แล้วสร้างกฎ'ccmp' TN conjunctsและ'ccmp' TN subjoinsเพื่อเข้าถึง glyph เหล่านี้ผ่านพินทุและ ZWJ ตามลำดับ พร้อมกับปรับรุ่น major ของฟอนต์เป็นรุ่น004(commit cc4935a) -
lanxang: ตัดกระบวนการแปลงพินทุ + พยัญชนะ
เป็นอักขระตัวห้อย/ตัวเฟื้อง และพยัญชนะ + ZWJ + พยัญชนะ
เป็นอักขระตัวควบ ทั้งหมด (ทิ้ง sequence ประกอบไว้อย่างนั้นในข้อความเลย แล้วให้ฟอนต์จัดการตอน render) ยกเว้นการควบ ໜ,ໝ เพื่ออำนวยความสะดวก (commit f0645b1) แต่ก็ยังป้อน ໜ, ໝ โดยตรงได้ด้วย level 3 เช่นกัน -
lanxang: เพิ่มผังแป้นพิมพ์อักษรไทยน้อยสำหรับ Windows ด้วย (commit cce81cd)
พร้อมกันนี้ก็แปลงวิธีลงรหัสอักขระไทยน้อยในตัวอย่างการปริวรรตทั้งหลายด้วย (พญาคันคาก, ฮีตคองคะลำ, บูชาพญานาค, นกกระจอก)
19 July 2025
Vee
My programming environment journey
No one actually cares about my programming environment journey, but I’ve often been asked to share it, perhaps for the sake of social media algorithms. I post it here, so later, I can copy and paste this conveniently.
My first computer, in the sense that I, not someone else, made the decision to buy it, ran Debian in 2002. It was a used Compaq desktop with a Pentium II processor, which I bought from Zeer Rangsit, a used computer market that may be the most famous in Thailand these days. When I got it home, I installed Debian right away. Before I bought my computer, I had used MBasic, mainly MS-DOS, Windows 3.1 (though rarely), and Solaris (remotely). For experimentation, I used Xenix, AIX, and one on DEC PDP-11 that I forgot.
Since I started with MBasic, that was my first programming environment. I learned Logo at a summer camp, so that became my second. Later, my father bought me a copy of Turbo Basic, and at school, I switched to Turbo Pascal.
After moving to GNU/Linux, I used more editors instead IDEs. From 1995 to 2010, my editors were pico, nvi, vim, TextMate, and Emacs paired with GCC (mostly C, not C++), PHP, Perl, Ruby, Python, JavaScript, and SQL. I also used VisualAge to learn Java in the 90s. I tried Haskell, OCaml, Objective C, Lua, Julia, and Scala too, but it was strictly for learning only.
After 2010, I used IntelliJ IDEA and Eclipse for Java and Kotlin. For Rust (instead of C), I used Emacs and Visual Studio Code. I explored Racket for learning purposes, then later started coding seriously in Clojure and Common Lisp. I tried using Vim 9.x and Neovim too, they were great, but not quite my cup of tea.
In 2025, a few days ago, I learned Smalltalk with Pharo to deepen my understanding of OOP and exploratory programming.
Update 2025/07/20: I forgot to mention xBase. In the '90s, I used it in a programming competition, but none of my programs in xBase reach production.
8 June 2025
Kitt
All photos here are AI-generated.
How convincing they are ..
I use Arch btw ..
6 April 2025
Thep
To USE or Not to USE for Lao Tham
จาก blog ที่แล้ว ผมได้เล่าถึงการรองรับอักษรธรรมในปัจจุบันที่ text shaping engine ต่างๆ หันมาใช้ Universal Shaping Engine (USE) ตามข้อกำหนดของไมโครซอฟท์ โดย USE เองเป็น engine ครอบจักรวาลที่มีการจัดการภายในตามคุณสมบัติของอักขระ Unicode เช่น การสลับสระหน้ากับพยัญชนะต้นสำหรับอักษรตระกูลพราหมี และเรียกใช้ OpenType feature ต่างๆ ในฟอนต์ตามลำดับที่กำหนดไว้
และการจัดการภายในของ USE ก็ทำให้มีข้อเสนอที่จะปรับโครงสร้างการลงรหัสข้อความอักษรธรรมเพื่อให้ทำงานกับ USE ได้ แต่มันก็ยังไม่เข้าที่เข้าทางนัก จึงเกิดแนวคิดที่จะหลบเลี่ยง USE แล้วทำทุกอย่างเองในฟอนต์ แต่ไปติดปัญหาที่ MS Word ที่ไม่ยอมให้หลบได้ง่ายๆ ทำให้เราอยู่บนทางแยกที่ต้องเลือกว่าจะใช้ USE ที่ยังไม่เข้าที่ หรือจะเลี่ยง USE ไปทำทุกอย่างเองโดยทิ้ง MS Word ไว้ข้างหลัง
blog นี้ก็จะวิเคราะห์ต่อ ว่าทางเลือกแต่ละทางมีข้อดีข้อเสียอย่างไร
Encoding แบบใหม่
ตามข้อเสนอในเอกสาร Structuring Tai Tham Unicode เมื่อตัดรายละเอียดที่อักษรธรรมลาว/อีสานไม่ใช้ออกไป ก็พอจะสรุปลำดับอักขระในข้อความได้เป็น:
S ::= CC (Vs | Vf)?
โดยที่ CC คือ consonant cluster พร้อมสระหน้า/ล่าง/บน วรรณยุกต์ สระหรือตัวสะกดปิดท้าย
CC ::= C M? V? T? F? C ::= [<ก>-<ฮ><อิลอย>-<โอลอย><แล><ส_สองห้อง><ตัวเลข>] | <ห><SAKOT>[<ก>-<ม>] M ::= <ระวง>? <ล_ล่าง>? (<SAKOT><ว>)? (<SAKOT><ย>)? V ::= Vp? Vb? Va? Vp ::= [<เอ>-<ไม้ม้วน>] // สระหน้า Vb ::= [<อุ>-<อู><ออ_ล่าง>] // สระล่าง Va ::= [<อิ>-<อือ><ไม้กง><ไม้เก๋าห่อนึ่ง>][<ไม้ซัด><ไม้กั๋ง>]? // สระบน T ::= [<ไม้เอก>-<ไม้โท>] F ::= Fs? [<ละทั้งหลาย><ไม้กั๋งไหล><ง_บน><ม_ล่าง><บ_ล่าง><ส_ล่าง><ไม้กั๋ง>]? (<SAKOT> S)? Fs ::= [<อ><ส_สองห้อง><ออย>] | <SAKOT>[<ก>-<ฬ>] // อ ของสระเอือ หรือ ตัวสะกด
สังเกตว่ามี recursion ใน F เพื่อแทนลูกโซ่ของพยางค์ในคำบาลีด้วย
ต่อจาก CC ก็จะตามด้วยสระกินที่ (spacing vowels) ซึ่งแบ่งเป็นสระมีตัวสะกด (Vs) และสระไม่มีตัวสะกด (Vf)
สำหรับสระมีตัวสะกด Vs คือสระอาหรือสระอำ (สระอำในอักษรธรรมไม่ได้มีรหัสอักขระเฉพาะเหมือนอักษรไทย แต่แทนด้วยสระอาตามด้วยไม้กั๋ง (นิคหิต) ความจริงอาจนับไม้กั๋งเป็นตัวสะกดในสระอำก็ได้ แต่กฎนี้พยายามจัดการสระอากับสระอำไปด้วยกัน กลายเป็นว่าสระอำก็ยังมีตัวสะกดได้อีก) พร้อมตัวสะกด Fs (ถ้ามี)
Vs ::= AV Fs? AV ::= [<อา><อาสูง>] <ไม้กั๋ง>? // สระอา สระอำ
ส่วนสระไม่มีตัวสะกด Vf ในตัวเนื้อหาของร่างฯ ได้บรรยายถึงสระเอาะและสระเอือะ แต่ในสรุปส่วนท้ายดูจะลืมสระเอาะไป และยังจัดการ อ ของสระเอือะซ้ำซ้อนกับใน Fs อีก
Vf ::= <อ>? <อะ> // วิสรรชนีย์ของสระเอือะ
Encoding แบบ USE
แม้ encoding แบบใหม่ที่เสนอมีจุดมุ่งหมายเพื่อให้วาดแสดงด้วย USE แต่เมื่อลองใช้กับ USE จริงกลับยังมี dotted circle เกิดขึ้นในหลายกรณี ซึ่งจากการทดลองก็พอจะสังเกตลักษณะของ USE ที่ต่างจากโครงสร้างที่เสนอในร่างดังนี้:
- ลำดับสระใน
Vสระบนมาก่อนสระล่าง ไม่ใช่ตามหลังสระล่างอย่างในร่างฯ ดังนั้นจึงอาจปรับกฎเป็น:V ::= Vp? Va? Vb?
- วรรณยุกต์อยู่หน้าสระกินที่ไม่ได้ แต่ตามหลังได้ และต้องอยู่ก่อนตัวสะกด ดูเหมือน USE จะนับ
Vsเป็นส่วนหนึ่งของV:V ::= Vp? Va? Vb? Vs?
ซึ่งถ้าเป็นเช่นนั้น ก็หมายความว่า USE ก็ยังต้องการการ reorder ให้วรรณยุกต์ไปอยู่ในตำแหน่งก่อนหน้าสระกินที่เพื่อให้สามารถซ้อนบนพยัญชนะได้ด้วย มันจะกลายเป็นความซับซ้อนเกินจำเป็นน่ะสิ
หลักการสำหรับการป้อนข้อความ
สมมติว่าเราใช้ encoding แบบ USE เราจะมีหลักในใจอย่างไร? เราจะใช้ลำดับการพิมพ์แบบที่เราเคยใช้กับอักษรไทยไม่ได้อีกแล้ว เพราะมันคือการ encode แบบกึ่ง visual ไม่ว่าเขาจะยืนยันที่จะเรียกว่า logical order
ยังไงก็ตาม แต่ลำดับการ encode นี้จะไม่ตรงกับลำดับการสะกดคำเสมอไป มันเน้นให้เรียงพิมพ์ได้เป็นหลัก! โดยมีลำดับแบบที่เรียกว่า logical order
มาหลอกให้งงเล่น
หลักการคือ
- ละทิ้งลำดับการสะกดในใจไว้ก่อน พิจารณารูปร่างของข้อความที่ต้องการ แล้ว encode ตามกฎในข้อถัดๆ ไป
- ผสมตัวห้อย ตัวเฟื้อง หรือระวง กับพยัญชนะต้นก่อน โดยมากเป็นตัวควบกล้ำ
- ตามด้วยสระ โดยถ้ามีสระหลายตัว ให้วางสระตามลำดับ หน้า, บน, ล่าง, ขวา
- ตามด้วยวรรณยุกต์
- ตามด้วยตัวสะกด ซึ่งอาจเป็นตัวห้อย, ตัวเฟื้อง, ไม้กั๋ง, ง สะกดบน, หรือไม้กั๋งไหล
- ถ้ามีการเชื่อมพยางค์เป็นลูกโซ่แบบบาลี ก็นับตัวสะกดเป็นพยัญชนะต้นของพยางค์ถัดไปแล้วใส่สระตามได้เลย
ความไม่ปกติของลำดับ
หลักการที่ว่าไปก็ดูปกติดีนี่? แต่ความซับซ้อนของอักษรธรรมทำให้มันไม่ตรงไปตรงมาอย่างนั้น ต่อไปนี้คือกรณีต่างๆ ที่ฝืนความรู้สึก อย่างน้อยก็ในระยะแรก
การสะกดแม่กกด้วยไม้ซัด
ไม้ซัดถือว่าเป็นสระบน (Va) ในกฎ ซึ่ง encoding ในร่างฯ สามารถตามหลังสระล่าง (Vb) ได้ แต่ตาม encoding ของ USE ต้องมาก่อนสระล่าง ดังนั้น เมื่อไม้ซัดทำหน้าที่เป็นตัวสะกดแม่กก จึงต้องใช้ลำดับที่ตัวสะกดมาก่อนสระ ไม่ใช่สระมาก่อนตัวสะกด

แต่ก็จะมีกรณีที่ไม่สามารถ encode ได้ ไม่ว่าจะตามร่างฯ หรือตาม USE คือเมื่อเป็นตัวสะกดของสระอา

อาจจะยกเว้นคำว่า นาค
ที่สามารถซ่อนลำดับไว้ภายใต้รูปเขียนพิเศษได้

เมื่อมีตัวห้อย/ตัวเฟื้องหรือสระระหว่าง cluster
การเขียนอักษรธรรมในหลายกรณีมีการใช้ตัวห้อย/ตัวเฟื้องเป็นพยัญชนะต้นของพยางค์ถัดไป แทนที่จะใช้ตัวเต็ม ซึ่งในกรณีเหล่านี้ ถ้าวางตัวห้อย/ตัวเฟื้องในตำแหน่งของตัวสะกด ก็จะไม่สามารถวางสระต่อได้อีก เพราะดูเหมือน USE ไม่ได้รองรับ recursion ใน F ตามกฎในร่างฯ และเมื่อแจงต่อไป CC ของพยางค์ถัดไปก็ขาดพยัญชนะต้นตัวเต็ม (C) มาขึ้นต้น CC แต่ถ้า encode โดยเลี่ยงให้ตัวห้อย/ตัวเฟื้องดังกล่าวเป็นส่วนหนึ่งของ CC ของพยางค์ก่อนหน้าก็จะสามารถวางสระต่อได้ แต่ลำดับก็จะดูขัดสามัญสำนึกสักหน่อย
แต่ในบางกรณีก็ไม่เอื้อให้ทำเช่นนั้น เช่น เมื่อมีสระมาคั่นในแบบที่ไม่สามารถสลับลำดับได้

ในคำย่อที่มีการยืมพยัญชนะต้น
บ่อยครั้งที่อักษรธรรมมีการใช้รูปเขียนย่อในลักษณะที่ใช้พยัญชนะต้นตัวเดียวซ้ำในพยางค์มากกว่าหนึ่งพยางค์ ในจำนวนนั้น บางคำอาจสามารถยังจัดลำดับอักขระจนเข้ากับกฎเกณฑ์ของ USE ได้ แม้จะดูเหมือนการเปลี่ยนหน้าที่อักขระ เช่น เปลี่ยนตัวสะกดมาเป็นตัวควบ หรืออาจมีการสลับลำดับสระของพยางค์ต่างๆ
แต่บางกรณีก็ไม่สามารถจัดลำดับให้เข้าเกณฑ์ได้

วิธีหลบเลี่ยง?
อย่างไรก็ดี ปัญหาทั้งหมดนี้สามารถหลบเลี่ยงได้ โดยลบ glyph DOTTED CIRCLE (uni25CC) ออกจากฟอนต์เสีย แล้ว USE ก็จะไม่แสดง dotted circle อีกเลย!

ที่กล่าวมาทั้งหมดนี้คือการทดสอบกับแอปที่ใช้ Harfbuzz แต่สุดท้าย เมื่อนำไปทดสอบกับ MS Word ปรากฏว่ามันก็ยังไม่ยอมง่ายๆ อยู่ดี โดยปัญหาหลักที่พบมีสองข้อ ข้อแรกคือกฎของตัวห้อย/ตัวเฟื้องจะไม่ทำงานถ้าไม่ได้ตามหลังพยัญชนะต้นทันที เช่น เป็นตัวสะกดของสระอา หรือมีสระอื่นมาคั่นกลาง กล่าวคือ
ดูจะถูกเรียกเฉพาะในตำแหน่งพยัญชนะซ้อนกันเท่านั้น ไม่เรียกในตำแหน่งตัวสะกด และอีกข้อหนึ่งคือกฎ ligature สำหรับ blwfนา
ไม่ทำงานเมื่อมีอักขระซ้อนบน/ล่าง

สรุป
ประเด็นต่างๆ ที่พบ พอจะสรุปได้ตังตาราง
| ประเด็น | ใช้ USE | เลี่ยง USE |
|---|---|---|
| วิธีการ |
|
|
| การ encode ข้อความ | กึ่ง visual (ขัดสามัญสำนึกนิดหน่อย) | ตามหลักการสะกดคำ |
| แอปที่รองรับ | Harfbuzz app*, MS Word (บางส่วน) | Harfbuzz app*, Notepad |
| อาการเมื่อไม่รองรับ |
|
|
*Harfbuzz app เช่น LibreOffice, Firefox, Gedit, Mousepad ฯลฯ
จึงพอสรุปได้ว่ายังมีความแตกต่างระหว่างข้อกำหนดในร่างฯ กับสิ่งที่ USE รองรับจริง ทำให้ไม่ว่าจะพยายามอย่างไรก็จะมีข้อบกพร่องเกิดขึ้นเสมอ และแอปที่มีปัญหาเสมอๆ ก็คือ MS Word
หากเลือกใช้ข้อกำหนด USE ทุกแอปที่รองรับ USE ก็จะได้การรองรับแบบ เกือบๆ
ครบถ้วน (โดย MS Word จะมีปัญหามากกว่าเพื่อนสักหน่อย) โดยแลกกับลำดับการ encode ที่ผิดธรรมชาติของผู้ใช้ ซึ่งเป็นการแลกที่ผมคิดว่าไม่คุ้ม เพราะจะมีผลให้เกิดเอกสารที่ encode แปลกๆ เกิดขึ้นในระหว่างที่ USE ยังไม่พร้อม แถมสิ่งที่ได้คืนมาก็ยังไม่ใช่สิ่งที่สมบูรณ์เสียด้วย
ในขณะที่หากเลือกหลีกเลี่ยง USE แอปส่วนใหญ่ยกเว้น MS Word ก็จะสามารถจัดแสดงอักษรธรรมได้สมบูรณ์ (ดังกล่าวไว้ใน blog ที่แล้ว) โดยที่ผู้ใช้ก็ยังคงใช้ encoding แบบเก่าได้เช่นเดิม และเมื่อไรที่ USE พร้อม ก็เพียงแปลง encoding ไปเป็นแบบใหม่ (ซึ่งอาจจะอัตโนมัติหรือ manual ก็ค่อยว่ากัน) โดยไม่ต้องมี encoding ชั่วคราวของ USE มาแทรกกลางเป็นชนิดที่สามให้เกิดความสับสนเพิ่ม โดยแลกกับการทิ้ง MS Word ที่ยังไงก็ไม่สมบูรณ์อยู่แล้ว และแนะนำให้ผู้ใช้อักษรธรรมใช้ LibreOffice หรือ Notepad (ซึ่งเป็นผลพลอยได้) ในการเตรียมเอกสารแทน ส่วนเว็บเบราว์เซอร์นั้นไม่เป็นปัญหา เพราะเบราว์เซอร์ส่วนใหญ่ก็ใช้ Harfbuzz เป็นฐานกันอยู่แล้ว การรองรับก็จะเหมือนๆ กับใน LibreOffice นั่นแล
ด้วยเหตุนี้ ผมจึงเลือกที่จะสร้างฟอนต์อักษรธรรมที่ หลีกเลี่ยง USE ต่อไป จนกว่า USE จะพร้อมจริงๆ
1 April 2025
Thep
Lao Tham Font vs USE
บันทึกการกลับมาทำฟอนต์อักษรธรรมอีกครั้ง หลังจาก commit ล่าสุด 4 ปีที่แล้ว โดยในช่วงหลังของการทำงานรอบนั้น มีความเปลี่ยนแปลงสำคัญใน Harfbuzz ก่อนที่ผมจะวางมือไปทำอย่างอื่น คือ มีการใช้ Universal Shaping Engine (USE) ตามข้อกำหนดของไมโครซอฟท์ ทำให้กฎบางข้อหยุดทำงาน เช่น การจัดการไม้กั๋งไหล (ลาวเรียก ไม้อังแล่น
) แต่ผมก็ไม่ได้ไปติดตาม
ในเอกสาร Creating and supporting OpenType fonts for the Universal Shaping Engine ของไมโครซอฟท์ ได้อธิบายขั้นตอนต่างๆ ที่ USE จะเรียกใช้กฎในฟอนต์ โดยที่ USE เองก็มีการประมวลผลภายในเองบางส่วนด้วย ตามแต่อักษรที่รองรับ โดยสำหรับอักษรธรรมก็มีเชิงอรรถให้ปวดใจว่า
Note: Tai Tham support is currently limited. Additional encoding work is required for full text representation to be possible.
การรองรับอักษรธรรมยังคงจำกัดอยู่ในตอนนี้ ยังต้องทำงานด้านการกำหนดรหัสกันต่อไปเพื่อจะให้ได้รหัสที่สามารถแทนข้อความได้เต็มที่
ซึ่งเมื่อไปตรวจสอบเอกสารที่เกี่ยวข้อง ก็พบเอกสาร Structuring Tai Tham Unicode (L2/19-365) โดย Martin Hosken ซึ่งเป็นร่างข้อเสนอที่จะปรับลำดับการลงรหัสอักขระอักษรธรรมจาก แบบเริ่มแรก (L2/05-095R) เพื่อการวาดแสดงด้วย USE ซึ่งลำดับแบบใหม่ค่อนข้างแตกต่างจากลำดับการสะกดในใจพอสมควร และข้อเสนอใหม่ก็ยังคงเป็นฉบับร่าง จึงเกิดความไม่แน่นอนว่าแนวทางการลงรหัสปัจจุบันจะเป็นแบบไหน
เนื่องจากพระอาจารย์ชยสิริ ชยสาโร ประสงค์จะให้ผมเพิ่มอักษรธรรมลงในฟอนต์ Laobuhan ของท่าน ผมจึงถือโอกาสทดลองทำตามข้อกำหนดของ USE อันใหม่เสียเลย โดยพยายามทดสอบบน Windows 11 ด้วย นอกเหนือจากที่เคยทดสอบเฉพาะบนลินุกซ์ โดยในข้อกำหนดใหม่ USE มีการ reorder สระหน้าให้ จึงไม่ต้องทำในฟอนต์เองอีกต่อไป สิ่งที่ควรทำ (เรียงตามลำดับการเรียกใช้โดย USE) จึงเป็น:
-
pref(Pre-base forms) เพื่อระบุตำแหน่งของระวง เพื่อที่ USE จะ reorder ไปไว้หน้าพยัญชนะต้นให้ในภายหลัง -
rphf(Reph forms) ความจริงเป็นกฎสำหรับ reorderเรผะ
ของอักษรอินเดีย ที่ดูแล้วน่าจะใช้กับไม้กั๋งไหล
ของอักษรธรรมได้ แต่เมื่อทดลองทำจริงแล้วไม่เป็นผล ซึ่งในเอกสารของไมโครซอฟท์เองก็ระบุไว้ว่า:Note that the category REPHA is not currently supported by USE.
ซึ่งหมายความว่าrphfเองก็จะยังไม่ทำงาน -
blwf(Below-base forms) เพื่อทำตัวห้อย ตัวเฟื้อง -
liga(Standard ligatures) เพื่อทำรูปเขียนพิเศษ เช่นนา
ผลการทดสอบคือ แอปที่ใช้ Harfbuzz (GTK, LibreOffice, Firefox) และ MS Word วาดแสดงอักษรธรรมได้ดี ยกเว้นในบางกรณี เช่น สระอาที่ตามหลังวรรณยุกต์จะมี dotted circle แทรกเข้ามา และตัว ล ห้อย (ที่ไม่ใช้ SAKOT) ที่ใช้ร่วมกับสระหน้าจะแสดงถูกต้องเฉพาะเมื่อลงรหัสด้วยลำดับที่เหมาะสมเท่านั้น กล่าวคือ ถ้าใช้ structure ข้อความแบบใหม่ที่ออกแบบให้รองรับ USE ก็ น่าจะ แสดงได้ถูกต้องเป็นส่วนมาก
 อักษรธรรมบน LibreOffice Writer แบบใช้ USE
อักษรธรรมบน LibreOffice Writer แบบใช้ USE
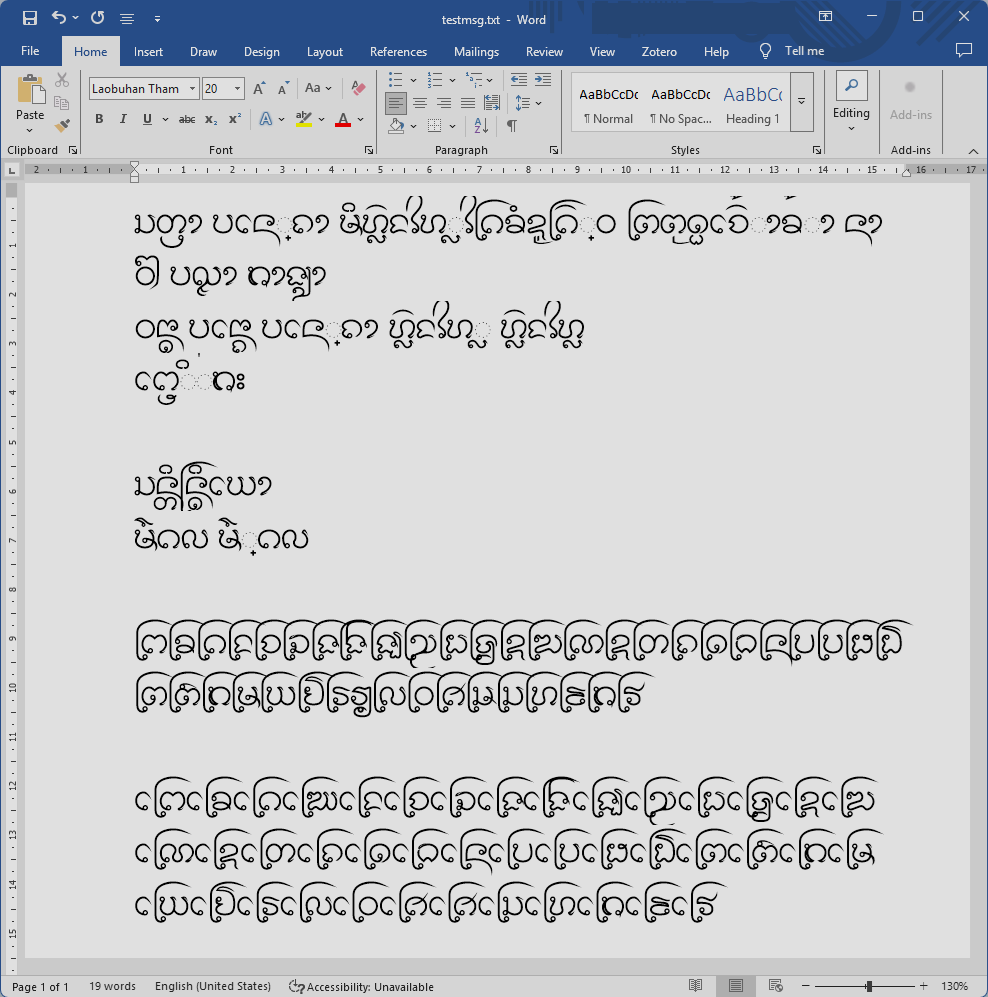 อักษรธรรมบน MS Word แบบใช้ USE
อักษรธรรมบน MS Word แบบใช้ USE
แต่กับ Notepad บน Windows ดูเหมือนกฎต่างๆ จะไม่ทำงานเลย! สถานการณ์อาจต่างจากลินุกซ์ที่แอปแทบทุกตัวใช้ Harfbuzz กันหมด แต่บน Windows ยังแยก implement กันอยู่
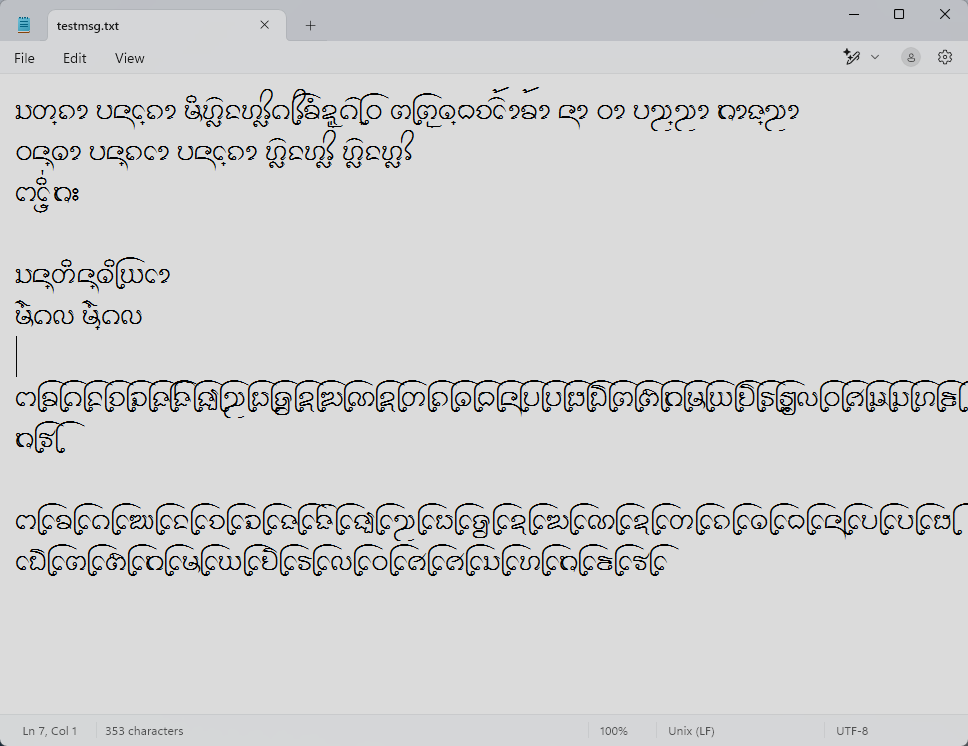 อักษรธรรมบน Windows Notepad แบบใช้ USE
อักษรธรรมบน Windows Notepad แบบใช้ USE
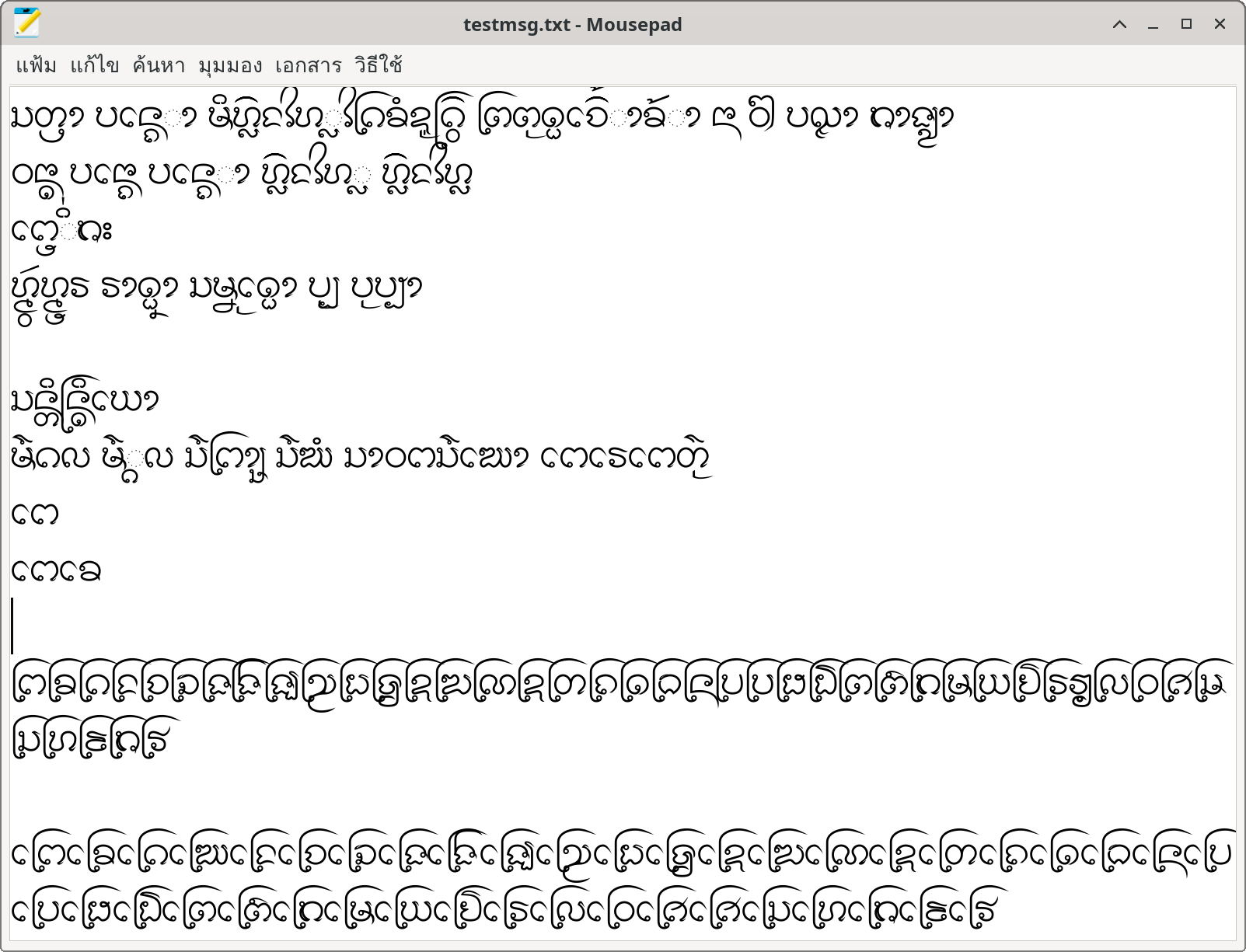 อักษรธรรมบน Linux Mousepad แบบใช้ USE
อักษรธรรมบน Linux Mousepad แบบใช้ USE
แต่ปัญหา dotted circle ในบางกรณีของ USE ก็ยังทำให้ผมต้องค้นหาข้อมูลต่อ ทั้งไล่ซอร์สโค้ดของ Harfbuzz ทั้งค้นเว็บ จนไปเจอ โพสต์ของ Richard Wordingham เล่าปัญหาเดียวกันที่เขาเจอ โดยได้พูดถึงวิธีหลบเลี่ยง USE ด้วย โดยในทุกกฎ GSUB, GPOS ไม่ต้องระบุรหัสอักษรเป็น
เลย เพียงใช้รหัสอักษร lana
ก็พอ ซึ่งถ้าเป็น Harfbuzz ก็จะไปเรียก default engine แทน USE ซึ่งฟอนต์ก็ต้องเตรียมกฎ GSUB ให้มันทำงานทุกอย่างแทน USE ทั้งหมด ผ่าน OpenType feature เท่าที่ใช้รองรับ Standard Scripts ซึ่งก็จะมี feature จำนวนจำกัดให้ใช้ เช่น DFLT
และ ccmp
เป็นต้นliga
เรื่องกฎไม่ใช่เรื่องยาก เพราะฟอนต์ Khottabun ที่ผมสร้างตั้งแต่ก่อนที่ Harfbuzz จะใช้ USE ก็ทำทุกอย่างเองหมดอยู่แล้ว ก็เลยหยิบมาทดลองได้ทันที โดยตัดรหัสอักษร
ออกจากกฎ lana
ที่ใช้ทั้งหมดccmp
ผลปรากฏว่า มันยังคงวาดแสดงได้อย่างสมบูรณ์บน Harfbuzz แต่คราวนี้มันทำงานบน Notepad บน Windows ด้วย! โดยในทั้งสองกรณี กฎที่เขียนไว้สำหรับไม้กั๋งไหลที่เคยไม่ทำงานบน Harfbuzz ก็กลับทำงานเรียบร้อย! (ดูตัวอย่างคำว่า มงฺคล แบบแรก)
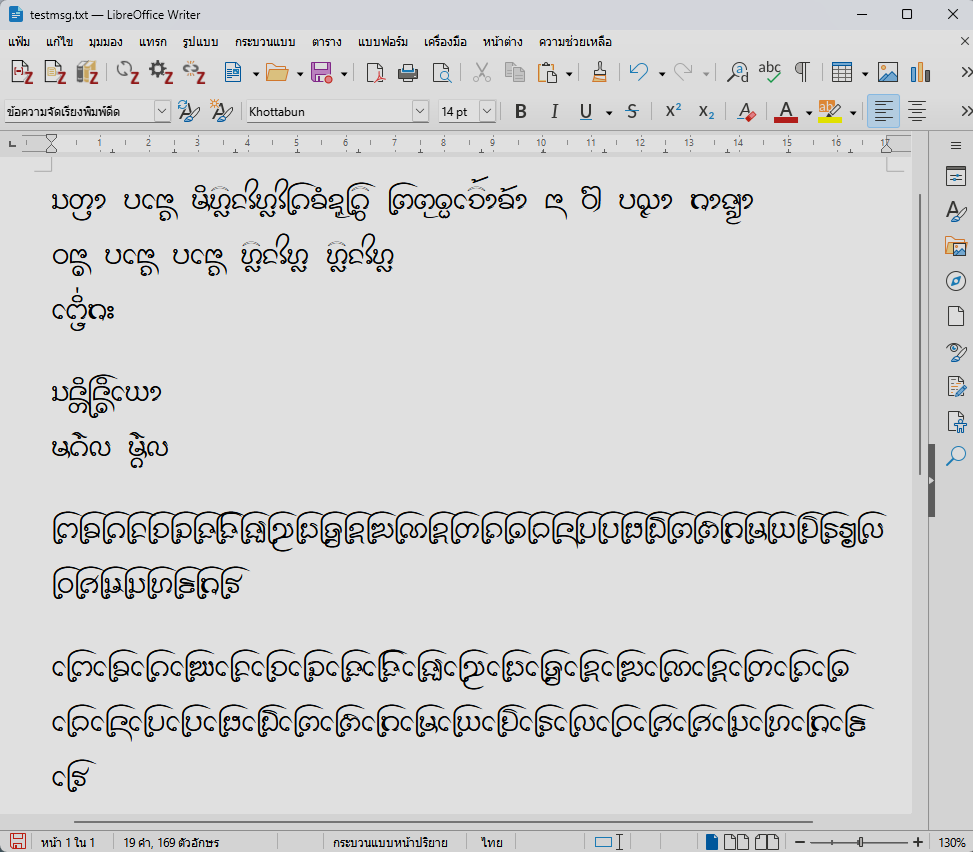 อักษรธรรมบน LibreOffice Writer แบบใช้รหัสอักษร
อักษรธรรมบน LibreOffice Writer แบบใช้รหัสอักษร DFLT อักษรธรรมบน Windows Notepad แบบใช้รหัสอักษร
อักษรธรรมบน Windows Notepad แบบใช้รหัสอักษร DFLTแต่ข่าวร้ายคือ มันเละบน MS Word
 อักษรธรรมบน MS Word แบบใช้รหัสอักษร
อักษรธรรมบน MS Word แบบใช้รหัสอักษร DFLTซึ่งจากการทดลองก็สรุปได้ว่ามันเกิดจาก:
- ข้อจำกัดของ
บน engine ของ MS Word ที่ดูจะไม่รองรับ contextual substitution ที่ซับซ้อน (เข้าใจว่าทำได้แค่ multiple substitution และ ligature substitution อย่างง่ายเท่านั้น)ccmp - engine ของ MS Word ยังคงใช้ USE เช่นเดิม ทำให้ถึงแม้จะเปลี่ยนไปใช้
ที่สามารถทำ contextual substitution ซับซ้อนได้ ก็จะเกิดการ reorder สระหน้าซ้ำซ้อนกันระหว่างโดยตัว engine เองก้บโดยกฎในฟอนต์จนสระหน้าสามารถเลื่อนข้ามพยัญชนะไปได้ถึง 2 ตำแหน่งliga
ถ้าคิดตามหลักเหตุผลแล้ว ถ้า
ที่ USE เรียกใช้ในขั้น preprocessing สามารถทำงานได้อย่างถูกต้อง โดยให้กฎแทรก glyph ผีสักตัว (เช่น ZWNJ) ไว้หน้าสระหน้าที่สลับลำดับแล้ว เพื่อให้มันคั่นระหว่างสระหน้ากับพยัญชนะที่อยู่ก่อนหน้าไว้ ก็ควรจะสามารถป้องกัน USE ไม่ให้ reorder ซ้ำอีกได้ แต่ในเมื่อ DirectWrite engine ที่ MS Word ใช้ไม่รองรับ ccmp
ที่ซับซ้อน (แบบที่ Harfbuzz ทำ) มันก็จบเห่ตั้งแต่ต้น ส่วน ccmp
หรือ liga
ที่รองรับ contextual substitution แบบซับซ้อนได้ ก็ถูกเรียกทำงานหลังการ reorder ภายในของ USE ไปแล้ว จึงไม่สามารถควบคุมอะไรได้ทันการณ์clig
ในเมื่อ USE ก็ไม่สมบูรณ์ จะเลี่ยง USE ก็ติดปัญหากับ MS Word ผมจึงอยู่บนทางเลือก:
- ใช้ USE ไปเลย แล้วรอให้มีการแก้ปัญหาของ USE อีกที
- เลี่ยง USE ต่อไป โดยได้การทำงานของไม้กั๋งไหลเพิ่มมาด้วย แต่ยอมทิ้งการรองรับบน MS Word
- เลี่ยง USE แบบต้องปรับฟอนต์ขนานใหญ่ให้ใช้
ในการ reorder ให้ได้ ผ่าน ligature glyph แล้วค่อยรื้อกลับใหม่อีกทีเมื่อ USE พร้อมccmp
การเลือกครั้งนี้จะไม่ยากเลยถ้าการรองรับอักษรธรรมใน Unicode มีทิศทางที่ชัดเจน แต่ปัญหาคือมันไม่ขยับมา 6 ปีแล้ว
แอปที่ใช้ Harfbuzz นั้นทำงานได้กับทุกทางเลือก ปัญหาอยู่ที่แอปนอกเหนือจากนั้น โดยในที่นี้คือ MS Word กับ Notepad ซึ่งเราต้องเลือกเอาอย่างใดอย่างหนึ่ง ถ้าใช้ USE ก็จะได้ MS Word ที่ทำงานได้เท่าที่ USE รองรับ ถ้าไม่ใช้ USE ก็จะได้ Notepad ที่ทำงานเต็มรูปแบบ
โดย Notepad เองก็ถือเป็นตัวแทนของแอปอื่นๆ ที่รองรับ OpenType แบบผิวเผินด้วย ในขณะที่ MS Word ก็น่าจะเป็นแอปหลักแอปหนึ่งที่ผู้ใช้ฟอนต์จะใช้เตรียมเอกสาร (แต่จะให้ดี LibreOffice เป็นทางเลือกที่เปิดกว้างต่อ solution ต่างๆ มากกว่า)
ผมจะวิเคราะห์ใน blog หน้าว่าจะพิจารณาชั่งน้ำหนักอย่างไรต่อไป
23 March 2025
Vee
I have been told to avoid linked lists.
I've been told to avoid linked lists because their elements are scattered everywhere, which can be true in some cases. However, I wonder what happens in loops, which I use frequently. I tried to inspect memory addresses of list elements of these two programs run on SBCL.
CL-USER> (setq *a-list* (let ((a nil)) (push 10 a) (push 20 a) (push 30 a) a))
(30 20 10)
CL-USER> (sb-kernel:get-lisp-obj-address *a-list*)
69517814583 (37 bits, #x102F95AB37)
CL-USER> (sb-kernel:get-lisp-obj-address (cdr *a-list*))
69517814567 (37 bits, #x102F95AB27)
CL-USER> (sb-kernel:get-lisp-obj-address (cddr *a-list*))
69517814551 (37 bits, #x102F95AB17)
CL-USER> (sb-kernel:get-lisp-obj-address (cddr *a-list*))
69517814551 (37 bits, #x102F95AB17)
CL-USER> (setq *a-list* (let ((a nil))
(push 10 a)
(push 20 a)
(push 30 a)
a))
(30 20 10)
CL-USER> (sb-kernel:get-lisp-obj-address *a-list*)
69518319943 (37 bits, #x102F9D6147)
CL-USER> (sb-kernel:get-lisp-obj-address (cdr *a-list*))
69518319927 (37 bits, #x102F9D6137)
CL-USER> (sb-kernel:get-lisp-obj-address (cddr *a-list*))
69518319911 (37 bits, #x102F9D6127)
In both programs, the list elements are not scattered. So, if scattered list elements were an issue for these simple cases, you probably used the wrong compiler or memory allocator.
18 March 2025
Kitt
GIMP 3.0 Released
The wait is over. Here we go .. https://www.gimp.org/news/2025/03/16/gimp-3-0-released/ We may need to update the scripts, though.
1 February 2025
Kitt
LLM Safety
เรื่องสมมติที่เกิดขึ้นจริง ในฝั่ง cybersecurity เราเริ่มใช้ AI ในการป้องกันมาพักนึงแล้ว และพบการโจมตีมากขึ้นเรื่อย ๆ รวมถึงเห็นภัยคุกคามใหม่ ๆ ที่เชื่อมโยงกับ AI ด้วยเหมือนกันในทางบวก ฝั่งป้องกัน เราใช้ AI ช่วยในการ summarize logs เชื่อมโยง security events เพื่อ discovery การโจมตี discover สิ่งที่ rule-based ทำไม่ได้ หรือ overload มนุษย์มาก ๆ ในทางลบ เราเห็น web crawlers / spiders ฝั่ง AI วิ่งเก็บข้อมูลหน้าเว็บหนักกว่าเดิม 5 – 10 เท่าจากปกติ ซึ่งมันกิน resources เด้อจ้า .. ทั้ง CPU, mem, egress ที่ต้องประมวลผลตอบสนอบขึ้นหมดเลย … Continue reading LLM Safety
29 January 2025
Kitt
DeepSeek-R1
ลองเอา deepseek-r1:1.5b ตัวเล็กสุด มารันใน notebook ตัวเอง มันเก่งจริงอย่างที่หลายคนอวยยศแฮะ response เร็ว กิน resource น้อย (อจก. ตามไปอ่าน architecture ของ deepseek แล้ว ในทางวิศวกรรม #ของแทร่ อยู่เด้อ) ประเด็นคือออ .. model ขนาด 1-2b parameters หลาย ๆ models นี่ คอมพิวเตอร์ทั่ว ๆ ไป มี memory เหลือสัก 1.5-2 GB ก็รันได้แล้วนะครับ ไม่ต้องมี GPU/NPU ช่วย accelerate ก็รันได้ (เครื่อง อจก. ก็ไม่มี GPU/NPU) ยิ่งถ้ามี AI-accelerated (e.g., CPU+NPU, Copilot+ PC) ที่กำลังทยอยออกมาวางขายผู้ใช้งานทั่วไป การรัน … Continue reading DeepSeek-R1
26 January 2025
Kitt
2025/1 Information on UTC – TAI
“NO leap second will be introduced at the end of June 2025. The difference between Coordinated Universal Time UTC and the International Atomic Time TAI is : from 2017 January 1, 0h UTC, until further notice : UTC-TAI = -37 s” — IERS EOP Bulletin C#69
AWS Thailand Region
มาแล้วก็ใช้สิครับ AWS Asia Pacific (Thailand) Region .. \(^^)/ ref. https://aws.amazon.com/local/thailand/
CVE: rsync
หัวทีม debian mirror แจ้งข่าวเข้า mailling list แต่เช้าว่า “สูเจ้าจงอัปเกรด rsync ASAP” ต้นเรื่องคือ 3.3 >= rsync >= 3.2.7 มี heap overflow และอื่น ๆ lot นี้ พบ และ fix ไปแล้ว ~ 6 CVEs ครับ main distros release fixes แล้วเมื่อไม่กี่ชั่วโมงที่ผ่านมา
หมูแฮม
ออกจากดาวหมา มาอยู่บ้านนี้สิบหกปี..วันนี้ลุงหมูแฮมได้กลับดาวละน้าาาาา
คืนชีพ skuld.kitty.in.th
10:00 31 ธ.ค. 2024 หลังจากที่ได้ instant ใหม่ OS เดิม (Ubuntu 16.04) เป็นเครื่องเปล่า ๆ ที่ไม่มีข้อมูล สิ่งแรกที่พยายามทำคือกู้จาก snapshot เดียวที่มีอยู่ ทำให้ได้ kitty.in.th ที่มีข้อมูลถึงประมาณต้นเดือนมีนาคม 2017 manually install All-in-One WP migration ทำ site backup ได้ไฟล์ขนาด 2 GB ซึ่งใหญ่เกิน จะ recovery ได้ฟรี แต่ก็ยังดีกว่าไม่มีอะไรเลย หลังจาก มี backup .wpress แล้ว dump mysql, tar gz web root เก็บ ย้ายมาเก็บที่ notebook อีกหนึ่งสำเนา พร้อมล้างเครื่องแล้ว .. กด … Continue reading คืนชีพ skuld.kitty.in.th
2024 Password Guidelines
รหัสผ่านไม่จำเป็นต้องมีสัญลักษณ์ผสมก็ได้ มันทำให้จำยาก พิมพ์ผิดง่าย และไม่ได้ช่วยให้ปลอดภัยอย่างที่เคยคิด แต่จะต้องตั้งรหัสผ่านให้ยาว ๆ (ต่ำสุด ๆ คือ 12 ตัวอักษร แนะนำว่า 15 ขึ้นไป) รหัสผ่านตั้งยาว ๆ ได้ ก็จะใช้ยาว ๆ ได้เลย ไม่จำเป็นต้องเปลี่ยนทุก 90 วันเหมือนที่เคยแนะนำกันอีกแล้ว จะใช้นานเท่าไหร่ก็ไม่ว่า จะบังคับเปลี่ยนก็ต่อเมื่อมีหลักฐานเพียงพอว่ารหัสผ่านรั่วไหล อย่าใช้รหัสผ่านเดียวกันหลายเว็บ/แอป มันมีความเสี่ยงที่เว็บ/แอป ทำรหัสผ่านเรารั่วไหล แล้วเอารหัสผ่านนั้นไป login เว็บอื่น ๆ ต่อ สำหรับคนที่กลัวจำรหัสผ่านยาว ๆ ไม่ได้ เรามีเทคโนโลยี password manager ช่วยตั้งและจำรหัสผ่านแทนได้นะครับ จะใช้ Google Chrome, Apple Password ไปเลยก็ได้ หรือจะใช้ LastPass, Dashlane, Bitwarden, 1Password ก็ได้ เดี๋ยวนี้ รหัสผ่านอย่างเดียวไม่พอจริง ๆ … Continue reading 2024 Password Guidelines